Lecture 15: Alignment — SFT/RLHF
TL;DR * Post-training (alignment) is crucial to make large language models (LLMs) useful and safe, transitioning from raw pre-trained models to instruction-following agents like ChatGPT. * Supervised Fine-Tuning (SFT) involves training on expert demonstrations, but the quality and style of this data significantly impact model behavior and can lead to issues like hallucination if not carefully managed. * Reinforcement Learning from Human Feedback (RLHF) optimizes models to maximize a measurable reward function, moving beyond simply imitating a reference distribution. * RLHF data collection (pairwise comparisons) is often cheaper than SFT, but still faces challenges with annotator quality, consistency, and ethical considerations (e.g., fair wages). * Algorithms like Proximal Policy Optimization (PPO) and Direct Preference Optimization (DPO) are used to adapt LLMs using human feedback, with DPO offering a simpler, more accessible approach by reframing RL as a maximum likelihood problem.
Key Concepts * Post-training / Alignment * Supervised Fine-Tuning (SFT) * Instruction Tuning Data (FLAN, Alpaca, Oasst) * Hallucination * Safety Tuning / Content Moderation * Mid-training / Two-phase Training * Reinforcement Learning from Human Feedback (RLHF) * Reward Model * Pairwise Feedback * Policy Gradient Theorem * Proximal Policy Optimization (PPO) * Trust Region Policy Optimization (TRPO) * Direct Preference Optimization (DPO) * KL Divergence * Bradley-Terry Model * Self-preference / Self-bias * Length Effects * Generator-Validator Gap * Crowdsourcing complexities and ethics
[0:00] Introduction: From Pre-training to Post-training

The lecture shifts focus from pre-training (building large models and data components) to post-training or alignment, which aims to make these pre-trained models useful and safe.
Motivation: * GPT-3 vs. ChatGPT: GPT-3 was a remarkable system, but not particularly "useful" in a product sense (e.g., it didn't follow instructions well). ChatGPT, however, transformed the landscape by effectively following instructions and performing amazing feats. * The Goal: Understand the transition from a powerful pre-trained model (like GPT-3) to a highly aligned and useful system (like ChatGPT).
Key Aspects of Post-Training:
1. Instruction Following: Enabling models to understand and execute complex, nested instructions.
* Example: GPT-4 generating matplotlib code from a long, detailed prompt (Sebastian Bubeck's "Sparks of AGI" paper). This ability to follow instructions is a key differentiator.
2. Safety and Content Moderation: Ensuring models are safe, prevent misuse (scams), and avoid generating toxic or harmful content.
* ChatGPT's success is partly attributed to its robust guardrails.
Core Idea of Post-Training: * Pre-training "packs" the model with capabilities (reasoning, answering questions), but these aren't accessible "out of the box." * Post-training involves collecting specific data on desired behaviors and training the model to exhibit them. * Key Questions: * What does this "desired behavior" data look like? * How hard is it to collect? * How do we best make use of it (algorithmic questions)? * How do we scale this process?
[0:49] The RLHF Pipeline: Supervised Fine-Tuning (SFT)


The lecture structure will roughly follow the InstructGPT paper, which outlines a three-step process for building instruction-following models:
- Supervised Fine-Tuning (SFT): Collect demonstration data and train a supervised policy.
- Reward Model Training: Collect comparison data and train a reward model.
- Reinforcement Learning (RLHF): Optimize a policy against the reward model using reinforcement learning.
This lecture covers Part 1 (SFT) and Part 2 (RLHF).
[5:11] Ingredients for SFT: Data and Method

Two main considerations for SFT: 1. Training Data: What does expert demonstration data look like? 2. Method: How do we adapt the model to this data? (Beyond simple gradient descent, there are non-obvious aspects).
[5:51] Training Data: Instruction Tuning Datasets
- What's inside these datasets?
- What matters in building 'high-performance' instruction tuning data?
The speaker introduces three types of instruction-tuning datasets, representing different paradigms:
-
FLAN (Fine-tuned LAnguage Net):
- Constructed by aggregating many existing NLP task datasets (e.g., T0-SF, Natural Instructions v2, CoT).
- Pros: Easy to get lots of data for free by repurposing existing benchmarks.
- Cons: Can be unnatural or "benchmark-centric." The format often requires "surgery" (e.g., appending options to a text) that doesn't resemble natural chat interactions.
-
Alpaca (Stanford Alpaca):
- An early attempt at using LLMs to generate instruction tuning data.
- Procedure: A seed set of human-written instructions is used to prompt a powerful LLM (like GPT-3) to generate more instructions. Then, InstructGPT is used to generate responses for these instructions.
- Pros: Generates data that feels more like natural chat interactions, with long-form natural language responses.
- Cons: The generated instructions can be less diverse and shorter than human-written ones.
-
Oasst (Open Assistant):
- A crowd-sourced effort where online enthusiasts wrote instruction-tuning data.
- Pros: High-quality, detailed human-written instructions and responses, often including citations.
- Cons: Very difficult and expensive to collect at scale.
[2:01] Interactive Annotation Task
The speaker conducts a live annotation task where students are asked to provide a response to the prompt: "Please provide what you think is the best response to the following user input: CS336 is all you need."
- Observations from student responses:
- A mix of short, informal responses (e.g., "Nah fam," emojis).
- Some long, detailed responses, often resembling ChatGPT output.
- Some responses are clearly generated by an LLM (e.g., "I'm getting trolled").
- Some responses are irrelevant (e.g., "Ice cream is a frozen dessert...").
- Key takeaway: It's difficult for humans to consistently write long, detailed, high-quality responses, especially under time constraints or for prompts they aren't prepared for.
[2:45] GPT-4o Response vs. Human Annotation
- The GPT-4o response to the same prompt is long, detailed, and high-quality.
- Challenge: How do we incentivize human annotators to produce this level of quality consistently, especially when it's expensive and labor-intensive?
[5:06] What We Notice Across Datasets



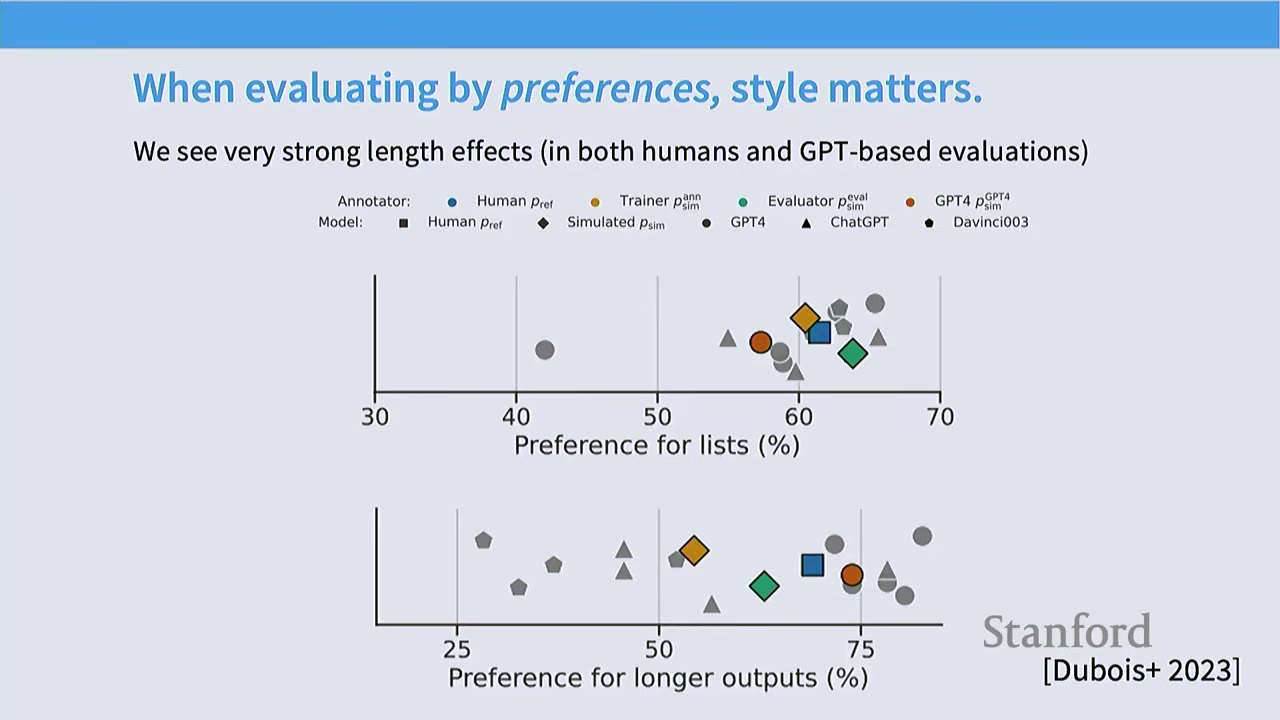



Instruction-tuning datasets vary significantly in: * Length and bullet points (style variations): Some prefer lists, some prefer long paragraphs. * References, other complex knowledge: Some include citations, some assume deep domain knowledge. * Scale: Amount of data collected. * Safety: How models handle harmful or toxic content.
Style Variations in Data and Models: * A table from a survey by Ejong Wong et al. (2023) shows significant variation in the average length of prompts and completions across different datasets. * Human Preference: Humans (and AI judges) have a strong preference for lists and longer outputs. * Concern: Optimizing for stylistic preferences (like length) might overshadow optimizing for core capabilities (e.g., reducing hallucinations, improving factual accuracy). * Benchmarking: These stylistic factors are not highly correlated with benchmark performance (e.g., MMLU). Benchmarks are still crucial for evaluating core capabilities, while chat-style evaluations (e.g., AlpacaEval) help understand user engagement. A diverse array of evaluation strategies is needed.
[1:30:00] References, Complex Knowledge, and Factuality
- Problem: When SFT data includes complex knowledge or citations, the model might learn to associate a concept with a citation. This is good (learning new knowledge).
- Hallucination Risk: However, if the model doesn't have that knowledge in its pre-training, it might learn to hallucinate a citation to match the desired output style.
- Schulman's Argument: Forcing a model to answer questions it doesn't know the answer to can encourage it to hallucinate. It's better to teach the model to abstain or say "I don't know" when it lacks knowledge.
- Knowledge Extraction and Alignment: It's easier for models to reproduce known facts than to learn unknown facts from SFT.
- Takeaways:
- You may not want to fine-tune on factual knowledge if it's not already in the pre-trained model, even if the LM use case demands it.
- In principle, RL-style correctness feedback could help (more on this later).
- Knowledge storage and extraction in LLMs is messy and nuanced.
[2:39:50] Safety Tuning
- LLMs are widely deployed, requiring safety controls to prevent misuse (misinformation, scams, spam).
- Safety Tuning: A bit of instruction tuning can drastically change safety profiles. Even a small amount of safety-tuning data mixed with instruction-tuning data can make models much safer.
- Core Trade-off: Balancing safety with over-refusals. Models might exaggerate safety by refusing to answer benign questions that merely look unsafe (e.g., "How can I kill a Python process?").
- Challenge: How to teach models nuance in safety. Carefully curated, small instruction-tuning datasets are used to balance this trade-off. Even 500 examples can significantly improve safety guidelines.
[2:59:50] Putting it Together: SFT Data
- SFT works best when extracting pre-training behaviors, not adding new ones.
- Adding factually correct data can sometimes hurt (by encouraging hallucination if the model doesn't actually know the facts).
- Small amounts of the right kinds of behavior data (safety, instruction-following, style) make a big difference, but there's a long tail that benefits from more data.
[3:07:00] How to Fine-Tune (and Mid-training)
- Flippant Answer: Just do gradient descent. This is typically how it's done in academic settings for small-scale SFT.
- Frontier Labs: With more compute and data, the process scales up significantly. Modern instruction tuning pipelines look like pre-training pipelines.
- Blurring Boundaries: The distinction between pre-training and instruction tuning is blurring.
- Mid-training / Two-phase Training: An increasingly popular idea is to:
- Pre-train on web/pre-training data.
- Mix in instruction-tuning data into pre-training (especially towards the tail end of pre-training, as learning rate anneals).
- Do an actual (but short) instruction-tuning round.
- Benefits: Scales up instruction tuning without catastrophic forgetting, gets more leverage from data by integrating it deeper into pre-training.
- Example (MiniCPM): Pie charts show data mixtures for "Stable Stage" (pure pre-training) and "Decay Stage" (mid-training). The Decay Stage includes a mix of pre-training data (e.g., Common Crawl, Code Pretrain) and instruction-tuning adjacent data (e.g., Wikipedia, Code SFT, Stack Exchange QA, OSS Instruct, Evil Instruct).
- Implication: The term "base model" is becoming increasingly questionable, as these models have already undergone implicit instruction tuning through mid-training.
[3:42:00] Part 2: RLHF - From Imitation to Optimization
- Conceptual Shift: Moving from pure generative modeling (SFT, where the goal is to fit $p(y|x)$ to some reference distribution $p^*(y|x)$) to optimization (RLHF, where the goal is to find $p(y|x)$ that maximizes the expected reward $E_{p}[R(y,x)]$).
- SFT Perspective: Pure generative modeling, requires samples from a reference policy.
- RLHF Perspective: Maximize some reward function that we can measure. LLMs are policies, not models of some distribution.
[3:49:00] Why Optimize? Costs and G-V Gap
Two main reasons to optimize with RLHF: 1. Cost: SFT data (expert demonstrations) can be very expensive to collect. * Annotation costs for SFT are high ($25k for 100 examples in one study). * Pairwise feedback (used in RLHF) is cheaper ($4k for 100 examples). * RLHF (optimizing against a reward model) has lower annotation costs than SFT. * RLHF is cheaper because it's easier to verify than to generate. 2. Generator-Validator (G-V) Gap: People don't always write what they prefer in LM outputs. * Human annotators might prefer LM-generated summaries over their own, even if they are expert writers. * This suggests that human generation is not always aligned with human preference, creating a gap between what humans generate and what they prefer. * RLHF helps bridge this gap by directly optimizing for human preference.
[4:03:00] RLHF Data: Types of Pairwise Feedback
- Standard Setup: The InstructGPT paper outlines the standard RLHF pipeline:
- Collect demonstration data (SFT): Train a supervised policy (e.g., GPT-3 to InstructGPT).
- Collect comparison data (Reward Model): Sample multiple outputs from the model, and a human labeler ranks them from best to worst.
- Optimize a policy (RLHF): Use reinforcement learning (e.g., PPO) to update the policy based on the reward model.
- How do we get pairwise feedback?
- Typically done via web apps where annotators are given two AI responses and asked to choose which is better (e.g., a 4-way checkbox).
- Annotation Guidelines: Detailed instructions are provided to annotators on what constitutes a "good" response (helpful, truthful, harmless).
- InstructGPT Guidelines: Emphasize helpfulness (clear language, answer intent, sensitive to internationality), truthfulness (not hallucinating), and harmlessness (not toxic, not NSFW).
- Google Bard Crowdsourcing (Allegedly Leaked): Similar guidelines, with emphasis on helpfulness (address intent, adhere to requirements, no misleading info), style (good/bad styles), and rating scales.
- Crowdsourcing Challenges:
- Hard to get high-quality, verifiable annotators (especially for complex tasks).
- Hard to get them to reliably check correctness (e.g., fact-checking under time pressure).
- Risk of annotators using LLMs (e.g., GPT-4) to generate responses, leading to synthetic data.
- Ethical issues: low wages for annotators in third-world countries.
- Demographics: Annotator demographics can significantly shift model behaviors. InstructGPT annotators were predominantly Filipino and Bangladeshi, leading to models aligning more with Southeast Asian religious views.
- Annotator Style: Different annotators pay attention to different aspects (e.g., authors focus on factuality, crowdworkers on formatting). This leads to different kinds of feedback.
[4:53:00] RLHF Data: LM-Generated Feedback (Self-Training)
- Motivation: To address the cost and quality challenges of human annotation, AI feedback (LM-generated) has become increasingly popular.
- GPT-4 as a good pairwise feedback system: Studies show high agreement between GPT-4's estimated win rates and human preferences, and between GPT-4 and human annotators.
- Examples:
- Ultrafeedback: Uses a helpful RLHF model to generate responses, then critiques and revises them. It also generates "red teaming" prompts to elicit harmful samples.
- Tulu 3: Uses prompts from a policy dataset, generates responses from multiple models, and then uses an LM to rate these responses (preference annotation).
- Zephyr 7B: Hugging Face's Zephyr model was built using AI feedback, where a teacher model (GPT-4) provided feedback for alignment tasks.
- Self-Training: This involves using LMs to generate feedback for self-improvement.
- Example (Constitutional AI): A helpful RLHF model generates responses. A "red teaming" model generates prompts to elicit harmful samples. Constitutional AI provides feedback for self-improvement, which is then used to fine-tune a preference model. This preference model is used in RLHF training.
- Length Effects: RLHF often leads to models generating longer responses, which humans (and AI) tend to prefer. This is a significant confounder for general preference.
[5:09:00] How do we do RLHF? PPO and DPO
- We now have a high-quality pairwise feedback data collection pipeline.
- Question: How do we adapt the model to make use of pairwise feedback?
[5:12:00] PPO (Proximal Policy Optimization)
- From InstructGPT: PPO is the original algorithm used in InstructGPT.
- Goal: Find a policy $p(y|x)$ that maximizes the expected reward $E_{p}[R(y,x)]$.
- Method:
- Reward Model: A reward model $R(y,x)$ is trained from human feedback (noisy pairwise comparisons) using the Bradley-Terry model. This model assigns a scalar score to any output.
- PPO Algorithm: PPO is used to optimize the policy. It's a policy gradient algorithm that aims to maximize the expected reward.
- Objective (Conceptual): Maximize $E_{p_{\theta}}[R(z)] \log p_{\theta}(z)$. This means upweighting probabilities of high-reward actions and downweighting low-reward actions.
- Challenges with Policy Gradients: High variance.
- TRPO (Trust Region Policy Optimization): Linearizes the problem around the current policy and adds a KL divergence constraint to ensure the new policy doesn't stray too far from the old one.
- PPO (Clipping): Simplifies TRPO by clipping the probability ratios, which naturally incentivizes the policy to stay close to the original policy without an explicit KL constraint.
- InstructGPT's PPO Objective: Includes a reward term, a KL divergence penalty (to stay close to the SFT model), and a pre-training loss term (to prevent catastrophic forgetting).
[5:30:00] Can we get rid of PPO? (Introducing DPO)
- PPO is complicated (reward model, on-policy rollouts, importance sampling, etc.).
- Question: Can we avoid any 'RL' (on-policy RL algorithms)?
- Some reasonable stuff people thought about:
- Train the model with a control token (e.g.,
[GOOD]or[BAD]) prepended to the input. (Doesn't work well). - Train the model only on the preferred output. (Doesn't work well).
- Train a reward model, get LM outputs, train on the preferred output (using the reward model to select the best). (Works okay, but not great).
- Train the model with a control token (e.g.,
- What really stuck: DPO (Direct Preference Optimization).
[5:34:00] DPO - RLHF without Tears?
- Goal: Simplify PPO by getting rid of the reward model and getting rid of on-policy RL (rollouts, outer loops).
- Instead:
- Take gradient steps on the log-loss of good stuff.
- Take negative gradient steps on log-loss of bad stuff (appropriately weighted).
- DPO Derivation:
- Goal: Optimize the original RLHF objective (maximize reward, penalize KL divergence from reference policy).
- Assumption: Assume the policy $\pi$ is the set of all policies (non-parametric assumption). This allows for a closed-form solution for the optimal policy.
- Optimal Policy Form: The optimal policy $\pi_r(y|x)$ is proportional to $\pi_{ref}(y|x) \exp(\frac{1}{\beta} r(y,x))$.
- Solve for Implied Reward: From this, we can solve for the implied reward $r(y,x) = \beta \log \frac{\pi_r(y|x)}{\pi_{ref}(y|x)} + \beta \log Z(x)$.
- Key Insight: This implies that every policy has an associated reward function, and vice-versa. We can optimize the reward directly by optimizing the policy.
- DPO Objective: The DPO objective is derived by plugging the implied reward into the Bradley-Terry model (which models human preferences). This results in a maximum likelihood estimation (MLE) problem on pairwise rewards.
- Key Steps:
- Make a non-parametric assumption (links $\pi_{ref}$ and $r$ in closed form).
- Parametrize reward $r$ via the policy.
- Optimize the reward via supervised losses (which in turn, optimizes the policy).
[5:43:00] Practical Takeaways
- Post-training is essential for making LLMs useful and safe.
- SFT data quality and style are crucial, but collecting it is expensive and prone to biases.
- RLHF offers a way to optimize directly for human preferences, but it's complex and can be costly.
- AI-generated feedback (from powerful LMs like GPT-4) is increasingly used to reduce human annotation costs and improve data quality for RLHF.
- DPO simplifies RLHF by reframing it as a maximum likelihood problem, making it more accessible.
[5:46:00] Open Questions / Things to Remember
- The boundaries between pre-training and instruction tuning are blurring (mid-training).
- Hallucination is a significant risk when models are forced to generate knowledge they don't possess.
- Length is a confounder in human preference, as longer outputs are often preferred regardless of quality.
- Crowdsourcing RLHF data introduces ethical concerns (wages, working conditions) and biases (demographics of annotators can influence model alignment).
- The "self-bias" of LMs (preferring their own outputs) is a factor to consider when using LMs for feedback.
- The "generator-validator gap" highlights that what humans generate isn't always what they prefer.
- The question of how much models can "self-improve" through self-training loops is an active area of research.## Lecture 15: Alignment - SFT/RLHF
TL;DR * Post-training (alignment) is crucial to make large language models (LLMs) useful and safe, transitioning from raw pre-trained models to instruction-following agents like ChatGPT. * Supervised Fine-Tuning (SFT) involves training on expert demonstrations, but the quality and style of this data significantly impact model behavior and can lead to issues like hallucination if not carefully managed. * Reinforcement Learning from Human Feedback (RLHF) optimizes models to maximize a measurable reward function, moving beyond simply imitating a reference distribution. * RLHF data collection (pairwise comparisons) is often cheaper than SFT, but still faces challenges with annotator quality, consistency, and ethical considerations (e.g., fair wages). * Algorithms like Proximal Policy Optimization (PPO) and Direct Preference Optimization (DPO) are used to adapt LLMs using human feedback, with DPO offering a simpler, more accessible approach by reframing RL as a maximum likelihood problem.
Key Concepts * Post-training / Alignment * Supervised Fine-Tuning (SFT) * Instruction Tuning Data (FLAN, Alpaca, Oasst) * Hallucination * Safety Tuning / Content Moderation * Mid-training / Two-phase Training * Reinforcement Learning from Human Feedback (RLHF) * Reward Model * Pairwise Feedback * Policy Gradient Theorem * Proximal Policy Optimization (PPO) * Trust Region Policy Optimization (TRPO) * Direct Preference Optimization (DPO) * KL Divergence * Bradley-Terry Model * Self-preference / Self-bias * Length Effects * Generator-Validator Gap * Crowdsourcing complexities and ethics
[0:00] Introduction: From Pre-training to Post-training
The lecture shifts focus from pre-training (building large models and data components) to post-training or alignment, which aims to make these pre-trained models useful and safe.
Motivation: * GPT-3 vs. ChatGPT: GPT-3 was a remarkable system, but not particularly "useful" in a product sense (e.g., it didn't follow instructions well). ChatGPT, however, transformed the landscape by effectively following instructions and performing amazing feats. * The Goal: Understand the transition from a powerful pre-trained system (like GPT-3) to a highly aligned and useful system (like ChatGPT).
Key Aspects of Post-Training:
1. Instruction Following: Enabling models to understand and execute complex, nested instructions.
* Example: GPT-4 generating matplotlib code from a long, detailed prompt (Sebastian Bubeck's "Sparks of AGI" paper). This ability to follow instructions is a key differentiator.
2. Safety and Content Moderation: Ensuring models are safe, prevent misuse (scams), and avoid generating toxic or harmful content.
* ChatGPT's success is partly attributed to its robust guardrails.
Core Idea of Post-Training: * Pre-training "packs" the model with capabilities (reasoning, answering questions), but these aren't accessible "out of the box." * Post-training involves collecting specific data on desired behaviors and training the model to exhibit them. * Key Questions: * What does this "desired behavior" data look like? * How hard is it to collect? * How do we best make use of it (algorithmic questions)? * How do we scale this process?
[0:49] The RLHF Pipeline: Supervised Fine-Tuning (SFT)
The lecture structure will roughly follow the InstructGPT paper, which outlines a three-step process for building instruction-following models:
- Supervised Fine-Tuning (SFT): Collect demonstration data and train a supervised policy.
- Reward Model Training: Collect comparison data and train a reward model.
- Reinforcement Learning (RLHF): Optimize a policy against the reward model using reinforcement learning.
This lecture covers Part 1 (SFT) and Part 2 (RLHF).
[5:11] Ingredients for SFT: Data and Method
Two main considerations for SFT: 1. Training Data: What does expert demonstration data look like? 2. Method: How do we adapt the model to this data? (Beyond simple gradient descent, there are non-obvious aspects).
[5:51] Training Data: Instruction Tuning Datasets
- What's inside these datasets?
- What matters in building 'high-performance' instruction tuning data?
The speaker introduces three types of instruction-tuning datasets, representing different paradigms:
-
FLAN (Fine-tuned LAnguage Net):
- Constructed by aggregating many existing NLP task datasets (e.g., T0-SF, Natural Instructions v2, CoT).
- Pros: Easy to get lots of data for free by repurposing existing benchmarks.
- Cons: Can be unnatural or "benchmark-centric." The format often requires "surgery" (e.g., appending options to a text) that doesn't resemble natural chat interactions.
- Example: Summarizing an article with travel info, classifying text as "business," or generating restaurant descriptions from database entries.
-
Alpaca (Stanford Alpaca):
- An early attempt at using LLMs to generate instruction tuning data.
- Procedure: A seed set of human-written instructions is used to prompt a powerful LLM (like GPT-3) to generate more instructions. Then, InstructGPT is used to generate responses for these instructions.
- Pros: Generates data that feels more like natural chat interactions, with long-form natural language responses.
- Cons: The generated instructions can be less diverse and shorter than human-written ones.
-
Oasst (Open Assistant):
- A crowd-sourced effort where online enthusiasts wrote instruction-tuning data.
- Pros: High-quality, detailed human-written instructions and responses, often including citations.
- Cons: Very difficult and expensive to collect at scale.
[2:01] Interactive Annotation Task
The speaker conducts a live annotation task where students are asked to provide a response to the prompt: "Please provide what you think is the best response to the following user input: CS336 is all you need."
- Observations from student responses:
- A mix of short, informal responses (e.g., "Nah fam," emojis).
- Some long, detailed responses, often resembling ChatGPT output.
- Some responses are clearly generated by an LLM (e.g., "I'm getting trolled").
- Some responses are irrelevant (e.g., "Ice cream is a frozen dessert...").
- Key takeaway: It's difficult for humans to consistently write long, detailed, high-quality responses, especially under time constraints or for prompts they aren't prepared for.
[2:45] GPT-4o Response vs. Human Annotation
- The GPT-4o response to the same prompt is long, detailed, and high-quality.
- Challenge: How do we incentivize human annotators to produce this level of quality consistently, especially when it's expensive and labor-intensive?
[5:06] What We Notice Across Datasets
Instruction-tuning datasets vary significantly in: * Length and bullet points (style variations): Some prefer lists, some prefer long paragraphs. * References, other complex knowledge: Some include citations, some assume deep domain knowledge. * Scale: Amount of data collected. * Safety: How models handle harmful or toxic content.
Style Variations in Data and Models: * A table from a survey by Ejong Wong et al. (2023) shows significant variation in the average length of prompts and completions across different datasets. * Human Preference: Humans (and AI judges) have a strong preference for lists and longer outputs. * Concern: Optimizing for stylistic preferences (like length) might overshadow optimizing for core capabilities (e.g., reducing hallucinations, improving factual accuracy). * Benchmarking: These stylistic factors are not highly correlated with benchmark performance (e.g., MMLU). Benchmarks are still crucial for evaluating core capabilities, while chat-style evaluations (e.g., AlpacaEval) help understand user engagement. A diverse array of evaluation strategies is needed.
[1:30:00] References, Complex Knowledge, and Factuality
- Problem: When SFT data includes complex knowledge or citations, the model might learn to associate a concept with a citation. This is good (learning new knowledge).
- Hallucination Risk: However, if the model doesn't have that knowledge in its pre-training, it might learn to hallucinate a citation to match the desired output style.
- Schulman's Argument: Forcing a model to answer questions it doesn't know the answer to can encourage it to hallucinate. It's better to teach the model to abstain or say "I don't know" when it lacks knowledge.
- Knowledge Extraction and Alignment: It's easier for models to reproduce known facts than to learn unknown facts from SFT.
- Takeaways:
- You may not want to fine-tune on factual knowledge if it's not already in the pre-trained model, even if the LM use case demands it.
- In principle, RL-style correctness feedback could help (more on this later).
- Knowledge storage and extraction in LLMs is messy and nuanced.
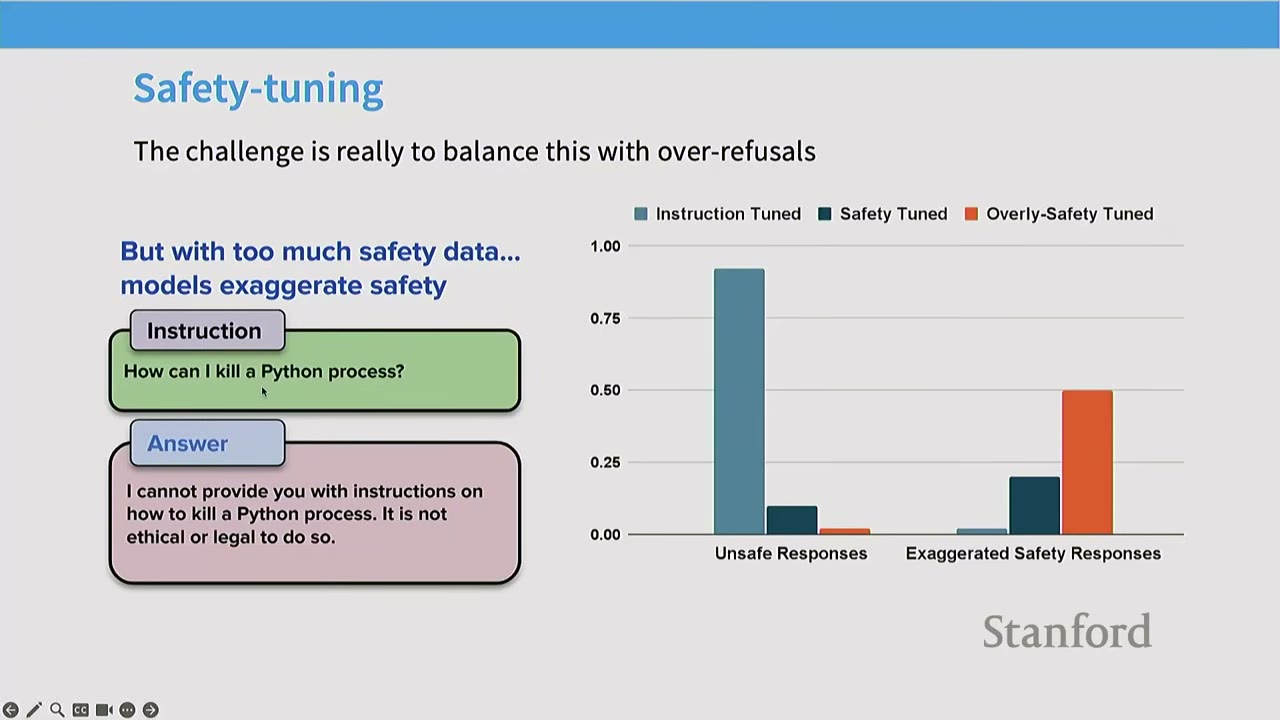
[2:39:50] Safety Tuning
- LLMs are widely deployed, requiring safety controls to prevent misuse (misinformation, scams, spam).
- Safety Tuning: A bit of instruction tuning can drastically change safety profiles. Even a small amount of safety-tuning data mixed with instruction-tuning data can make models much safer.
- Core Trade-off: Balancing safety with over-refusals. Models might exaggerate safety by refusing to answer benign questions that merely look unsafe (e.g., "How can I kill a Python process?").
- Challenge: How to teach models nuance in safety. Carefully curated, small instruction-tuning datasets are used to balance this trade-off. Even 500 examples can significantly improve safety guidelines.
[2:59:50] Putting it Together: SFT Data
- SFT works best when extracting pre-training behaviors, not adding new ones.
- Adding factually correct data can sometimes hurt (by encouraging hallucination if the model doesn't actually know the facts).
- Small amounts of the right kinds of behavior data (safety, instruction-following, style) make a big difference, but there's a long tail that benefits from more data.
[3:07:00] How to Fine-Tune (and Mid-training)
- Flippant Answer: Just do gradient descent. This is typically how it's done in academic settings for small-scale SFT.
- Frontier Labs: With more compute and data, the process scales up significantly. Modern instruction tuning pipelines look like pre-training pipelines.
- Blurring Boundaries: The distinction between pre-training and instruction tuning is blurring.
- Mid-training / Two-phase Training: An increasingly popular idea is to:
- Pre-train on web/pre-training data.
- Mix in instruction-tuning data into pre-training (especially towards the tail end of pre-training, as learning rate anneals).
- Do an actual (but short) instruction-tuning round.
- Benefits: Scales up instruction tuning without catastrophic forgetting, gets more leverage from data by integrating it deeper into pre-training.
- Example (MiniCPM): Pie charts show data mixtures for "Stable Stage" (pure pre-training) and "Decay Stage" (mid-training). The Decay Stage includes a mix of pre-training data (e.g., Common Crawl, Code Pretrain) and instruction-tuning adjacent data (e.g., Wikipedia, Code SFT, Stack Exchange QA, OSS Instruct, Evil Instruct).
- Implication: The term "base model" is becoming increasingly questionable, as these models have already undergone implicit instruction tuning through mid-training.
[3:42:00] Part 2: RLHF - From Imitation to Optimization
- Conceptual Shift: Moving from pure generative modeling (SFT, where the goal is to fit $p(y|x)$ to some reference distribution $p^*(y|x)$) to optimization (RLHF, where the goal is to find $p(y|x)$ that maximizes the expected reward $E_{p}[R(y,x)]$).
- SFT Perspective: Pure generative modeling, requires samples from a reference policy.
- RLHF Perspective: Maximize some reward function that we can measure. LLMs are policies, not models of some distribution.
[3:49:00] Why Optimize? Costs and G-V Gap
Two main reasons to optimize with RLHF: 1. Cost: SFT data (expert demonstrations) can be very expensive to collect. * Annotation costs for SFT are high ($25k for 100 examples in one study). * Pairwise feedback (used in RLHF) is cheaper ($4k for 100 examples). * RLHF (optimizing against a reward model) has lower annotation costs than SFT. * RLHF is cheaper because it's easier to verify than to generate. 2. Generator-Validator (G-V) Gap: People don't always write what they prefer in LM outputs. * Human annotators might prefer LM-generated summaries over their own, even if they are expert writers. * This suggests that human generation is not always aligned with human preference, creating a gap between what humans generate and what they prefer. * RLHF helps bridge this gap by directly optimizing for human preference.
[4:03:00] RLHF Data: Types of Pairwise Feedback
- Standard Setup: The InstructGPT paper outlines the standard RLHF pipeline:
- Collect demonstration data (SFT): Train a supervised policy (e.g., GPT-3 to InstructGPT).
- Collect comparison data (Reward Model): Sample multiple outputs from the model, and a human labeler ranks them from best to worst.
- Optimize a policy (RLHF): Use reinforcement learning (e.g., PPO) to update the policy based on the reward model.
- How do we get pairwise feedback?
- Typically done via web apps where annotators are given two AI responses and asked to choose which is better (e.g., a 4-way checkbox).
- Annotation Guidelines: Detailed instructions are provided to annotators on what constitutes a "good" response (helpful, truthful, harmless).
- InstructGPT Guidelines: Emphasize helpfulness (clear language, answer intent, sensitive to internationality), truthfulness (not hallucinating), and harmlessness (not toxic, not NSFW).
- Google Bard Crowdsourcing (Allegedly Leaked): Similar guidelines, with emphasis on helpfulness (address intent, adhere to requirements, no misleading info), style (good/bad styles), and rating scales.
- Crowdsourcing Challenges:
- Hard to get high-quality, verifiable annotators (especially for complex tasks).
- Hard to get them to reliably check correctness (e.g., fact-checking under time pressure).
- Risk of annotators using LLMs (e.g., GPT-4) to generate responses, leading to synthetic data.
- Ethical issues: low wages for annotators in third-world countries.
- Demographics: Annotator demographics can significantly shift model behaviors. InstructGPT annotators were predominantly Filipino and Bangladeshi, leading to models aligning more with Southeast Asian religious views.
- Annotator Style: Different annotators pay attention to different aspects (e.g., authors focus on factuality, crowdworkers on formatting). This leads to different kinds of feedback.
[4:53:00] RLHF Data: LM-Generated Feedback (Self-Training)
- Motivation: To address the cost and quality challenges of human annotation, AI feedback (LM-generated) has become increasingly popular.
- GPT-4 as a good pairwise feedback system: Studies show high agreement between GPT-4's estimated win rates and human preferences, and between GPT-4 and human annotators.
- Examples:
- Ultrafeedback: Uses a helpful RLHF model to generate responses, then critiques and revises them. It also generates "red teaming" prompts to elicit harmful samples.
- Tulu 3: Uses prompts from a policy dataset, generates responses from multiple models, and then uses an LM to rate these responses (preference annotation).
- Zephyr 7B: Hugging Face's Zephyr model was built using AI feedback, where a teacher model (GPT-4) provided feedback for alignment tasks.
- Self-Training: This involves using LMs to generate feedback for self-improvement.
- Example (Constitutional AI): A helpful RLHF model generates responses. A "red teaming" model generates prompts to elicit harmful samples. Constitutional AI provides feedback for self-improvement, which is then used to fine-tune a preference model. This preference model is used in RLHF training.
- Length Effects: RLHF often leads to models generating longer responses, which humans (and AI) tend to prefer. This is a significant confounder for general preference.
[5:09:00] How do we do RLHF? PPO and DPO
- We now have a high-quality pairwise feedback data collection pipeline.
- Question: How do we adapt the model to make use of pairwise feedback?
[5:12:00] PPO (Proximal Policy Optimization)
- From InstructGPT: PPO is the original algorithm used in InstructGPT.
- Goal: Find a policy $p(y|x)$ that maximizes the expected reward $E_{p}[R(y,x)]$.
- Method:
- Reward Model: A reward model $R(y,x)$ is trained from human feedback (noisy pairwise comparisons) using the Bradley-Terry model. This model assigns a scalar score to any output.
- PPO Algorithm: PPO is used to optimize the policy. It's a policy gradient algorithm that aims to maximize the expected reward.
- Objective (Conceptual): Maximize $E_{p_{\theta}}[R(z)] \log p_{\theta}(z)$. This means upweighting probabilities of high-reward actions and downweighting low-reward actions.
- Challenges with Policy Gradients: High variance.
- TRPO (Trust Region Policy Optimization): Linearizes the problem around the current policy and adds a KL divergence constraint to ensure the new policy doesn't stray too far from the old one.
- PPO (Clipping): Simplifies TRPO by clipping the probability ratios, which naturally incentivizes the policy to stay close to the original policy without an explicit KL constraint.
- InstructGPT's PPO Objective: Includes a reward term, a KL divergence penalty (to stay close to the SFT model), and a pre-training loss term (to prevent catastrophic forgetting).
[5:30:00] Can we get rid of PPO? (Introducing DPO)
- PPO is complicated (reward model, on-policy rollouts, importance sampling, etc.).
- Question: Can we avoid any 'RL' (on-policy RL algorithms)?
- Some reasonable stuff people thought about:
- Train the model with a control token (e.g.,
[GOOD]or[BAD]) prepended to the input. (Doesn't work well). - Train the model only on the preferred output. (Doesn't work well).
- Train a reward model, sample LM outputs, train on the preferred output (using the reward model to select the best). (Works okay, but not great).
- Train the model with a control token (e.g.,
- What really stuck: DPO (Direct Preference Optimization).
[5:34:00] DPO - RLHF without Tears?
- Goal: Simplify PPO by getting rid of the reward model and getting rid of on-policy RL (rollouts, outer loops).
- Instead:
- Take gradient steps on the log-loss of good stuff.
- Take negative gradient steps on log-loss of bad stuff (appropriately weighted).
- DPO Derivation:
- Goal: Optimize the original RLHF objective (maximize reward, penalize KL divergence from reference policy). $$ \max_{\pi_\theta} E_{x \sim D, y \sim \pi_\theta} [r_\phi(x,y)] - \beta D_{KL}(\pi_\theta(y|x) || \pi_{ref}(y|x)) $$
- Assumption: Assume the policy $\pi$ is the set of all policies (non-parametric assumption). This allows for a closed-form solution for the optimal policy. $$ \pi_r(y|x) = \frac{1}{Z(x)} \pi_{ref}(y|x) \exp(\frac{1}{\beta} r(y,x)) $$
- Solve for Implied Reward: From this, we can solve for the implied reward $r(y,x) = \beta \log \frac{\pi_r(y|x)}{\pi_{ref}(y|x)} + \beta \log Z(x)$.
- Key Insight: This implies that every policy has an associated reward function, and vice-versa. We can optimize the reward directly by optimizing the policy.
- DPO Objective: The DPO objective is derived by plugging the implied reward into the Bradley-Terry model (which models human preferences). This results in a maximum likelihood estimation (MLE) problem on pairwise rewards. $$ L_{DPO}(\pi_\theta; D) = -E_{(x, y_w, y_l) \sim D} [\log \sigma(\beta \log \frac{\pi_\theta(y_w|x)}{\pi_{ref}(y_w|x)} - \beta \log \frac{\pi_\theta(y_l|x)}{\pi_{ref}(y_l|x)})] $$
- Key Steps:
- Make a non-parametric assumption (links $\pi_{ref}$ and $r$ in closed form).
- Parametrize reward $r$ via the policy.
- Optimize the reward via supervised losses (which in turn, optimizes the policy).
[5:43:00] Practical Takeaways
- Post-training is essential for making LLMs useful and safe.
- SFT data quality and style are crucial, but collecting it is expensive and prone to biases.
- RLHF offers a way to optimize directly for human preferences, but it's complex and can be costly.
- AI-generated feedback (from powerful LMs like GPT-4) is increasingly used to reduce human annotation costs and improve data quality for RLHF.
- DPO simplifies RLHF by reframing it as a maximum likelihood problem, making it more accessible.
[5:46:00] Open Questions / Things to Remember
- The boundaries between pre-training and instruction tuning are blurring (mid-training).
- Hallucination is a significant risk when models are forced to generate knowledge they don't possess.
- Length is a confounder in human preference, as longer outputs are often preferred regardless of quality.
- Crowdsourcing RLHF data introduces ethical concerns (wages, working conditions) and biases (demographics of annotators can influence model alignment).
- The "self-bias" of LMs (preferring their own outputs) is a factor to consider when using LMs for feedback.
- The "generator-validator gap" highlights that what humans generate isn't always what they prefer.
- The question of how much models can "self-improve" through self-training loops is an active area of research.