TL;DR
* Data is the most critical component for successful language models, often more so than architecture or scaling laws.
* Data collection and processing is a complex, multi-stage pipeline involving raw data acquisition, conversion, filtering, and deduplication.
* Companies are often secretive about their data sources and processing techniques due to competitive dynamics and legal/copyright concerns.
* The field of data curation is highly heuristic, with various approaches (rule-based, model-based, synthetic generation) constantly evolving.
* Copyright law and terms of service significantly impact what data can be legally and practically used for training models.
Key concepts
* Pre-training, Mid-training, Post-training
* Data Sources: BooksCorpus, Wikipedia, WebText, Common Crawl, C4, The Pile, GitHub, StackExchange, RefinedWeb, FineWeb, Dolma, LLaMA, NemoTron-CC
* Data Processing: Filtering (rule-based vs. model-based), Deduplication, Language Identification, Quality Filtering, Toxicity Filtering, Anonymization, Synthetic Data Generation, Self-Instruct, RLHF
* Copyright Law: Intellectual Property, Fair Use (purpose, nature, amount, market effect), Licenses (Creative Commons), Terms of Service
* Long Context
* Instruction Following / Chat Data
[0:00] Introduction: The Importance of Data
0:10 A lecturer stands behind a podium with a laptop, gesturing while speaking.0:27 Python code for lecture_13.py, outlining topics on training models and data selection.1:10 Slide section "Pre-Training Data" detailing dataset creation and data cleaning methods.
The focus of this lecture is on data for language models.
Hot Take: Data is the most important thing in getting language models right.
* Some might disagree, arguing that scaling laws are more important.
* Justification: Companies are often transparent about model architecture and training procedures (e.g., LLaMA 3, DeepSeek fully disclose these), but they are typically very secretive about their data. This secrecy suggests data is a key differentiator.
* Reasons for Secrecy:
1. Competitive Dynamics: Data pipelines and curation methods are proprietary and give companies an edge.
2. Copyright Liability: Companies want to avoid lawsuits related to data usage.
Before foundation models, data annotation for supervised learning was clearly recognized as important. Now, even with less annotation, significant curation and cleaning are still required.
Data is fundamentally a "long-tail problem."
* It's highly scalable: you can hire hundreds of people to work on different aspects of data (multilinguality, code, images, etc.).
* In contrast, architecture design is often handled by a small, focused team.
[2:52] Stages of Training
Language model training typically involves multiple stages:
Pre-training: Training on raw, large-scale data (e.g., from the web). This is the primary focus of this lecture.
Mid-training: Curating smaller sets of high-quality data (documents) to target particular capabilities (e.g., math, code, long context).
Post-training: Fine-tuning on instruction-following data, chat data, or using reinforcement learning (RLHF) to align the model with human preferences and ensure safety.
In practice, the lines between these stages can be blurry, and more stages might be involved in recent models. The basic idea is to start with large amounts of low-quality data and progressively refine training on smaller amounts of high-quality data.
Terminology:
* Base model: Refers to the checkpoint after pre-training and mid-training.
* Instruct/Chat model: Refers to the model after post-training.
[4:09] Example: OLMo (from AI2)
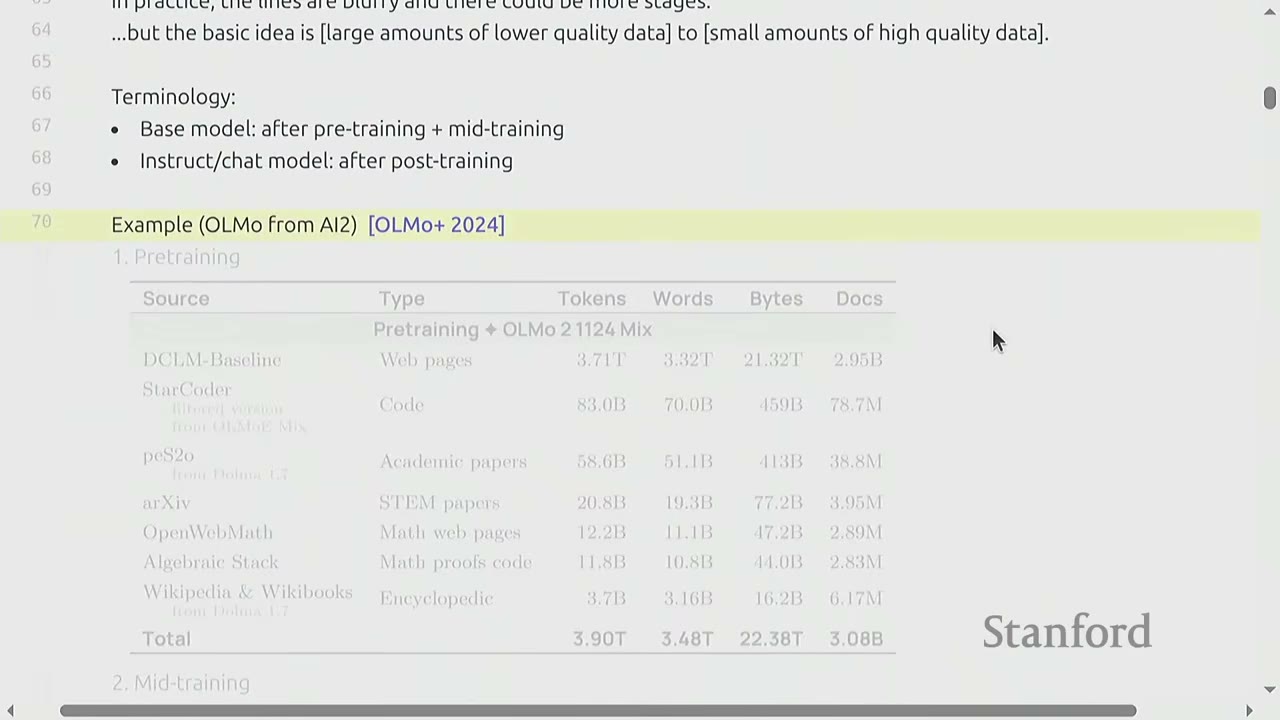
4:12 Table showing pretraining data statistics for OLMo+ 2024, including tokens, words, bytes, and docs.
Let's look at the data mix for OLMo, an open-source model from AI2 (OLMo+ 2024 paper).
1. Pre-training Data Mix:
Source
Type
Tokens (billions)
Words (billions)
Bytes (billions)
Docs (millions)
DCLM-Baseline
Web pages
3.71
3.32
21.32
2.95
StarCoder
Code
83.0
70.0
413
78.8
peS2o
Academic papers
58.6
51.1
413
38.8
arXiv
Math papers
20.8
19.3
77.2
2.89
OpenWebMath
Math web pages
12.2
11.1
47.2
3.08
Algebraic Stack
Math proofs code
1.8
1.7
6.2
0.17
Wikipedia & WikiBooks
Encyclopedia
1.7
1.6
6.2
0.47
Total
3.90T
3.48T
22.38T
3.08B
DCLM-Baseline: A web crawl dataset.
StarCoder: Code from GitHub.
peS2o: Academic papers, likely from Semantic Scholar.
2. Mid-training Data Mix:
This stage focuses on higher quality data, often a subset of pre-training data or synthetically generated data.
Source
Type
Tokens (billions)
Words (billions)
Bytes (billions)
Docs (millions)
DCLM-Baseline
High quality web
752
670
4.56T
606
FLAN
Instruction data
17.0
14.4
98.2
57.3
peS2o
Academic papers
58.6
51.1
413
38.8
Wikipedia & WikiBooks
Encyclopedia
3.7
3.1
16.2
2.48
Stack Exchange
Q&A
1.26
1.14
7.72
6.17
High quality total
832.6B
739.8B
5.09T
710.8M
TuluMath
Synthetic math
230
222
1.03T
220K
TinyGSM-Mind
Synthetic math
28.7
28.1
163
17K
DolminoSynthMath
Synthetic math
6.48
5.68
25.5
125
MathCoder2
Synthetic math
3.87
3.71
18.4
2.83M
Metamath
Math
84.2
76.6
37.4
7.8K
CodeSearchNet
Code
1.78
1.41
29.8
7.2K
GSM8K
Math
2.74
2.59
9.73
21.37M
Train split
10.7B
9.73B
45.9B
21.37M
Notice the DCLM-Baseline is filtered down from 3.7T to 752B tokens.
FLAN: Instruction data.
Stack Exchange: Q&A data.
Synthetic math data (TuluMath, TinyGSM-Mind, DolminoSynthMath, MathCoder2).
Metamath, CodeSearchNet, GSM8K: Math and code specific datasets.
3. Post-training Data Mix:
This stage focuses on instruction following and safety.
Category
Prompt Dataset
Count
# Prompts used in SFT
# Prompts used in DPO
# References
General
Tulu 3 Hardcoded
88
24
7
24
OpenAssistant 1.2.1
24
7,130
7,130
24
No Robots
9,500
9,500
9,500
24
WildChat (GPT-4 subset)
89,892
89,892
0
24
Ultrafeedback v2
41,635
41,635
0
24
FLAN v2.1
89,982
89,982
0
24
SciRIFF
15,000
15,000
0
24
Recall
Tulu 3 Persona Math
149,960
149,960
0
24
Table QA
Tulu 3 Persona Math
149,960
149,960
0
24
Reasoning
Tulu 3 GSM
19,980
19,980
0
24
Tulu 3 Persona Algebra
19,980
19,980
0
24
OpenMathInstruct-2
64,312
64,312
0
24
Coding
NumaMath-IR
20,000
20,000
0
24
Tulu 3 CodeCoCo
10,000
10,000
0
24
Safety-Compliance
Tulu 3 WildJailbreak
50,000
50,000
0
24
& Non-Compliance
Tulu 3 WildGuardMix
50,000
50,000
0
24
Multilingual
Aya
29,980
29,980
0
24
Precise IF
Tulu 3 Persona IF
19,980
19,980
0
24
Augmented IF
Tulu 3 IF-augmented
65,530
65,530
0
24
Total
939,927
939,927
425,147
This stage involves various chat-like datasets and synthetically generated data for specific capabilities.
[5:40] What are these datasets? How are they chosen and processed?
There isn't a formal, principled way to decide these things. It's often heuristic.
[6:15] Pre-training: Data of Popular Models
Let's peer into the data of some popular models, starting from earlier models and moving to more recent ones.
[6:50] BERT (Devlin+ 2018)
6:50 Python code snippet listing popular models and their data sources for pretraining.8:36 Lecturer at podium, with a slide showing details about Smashwords, BooksCorpus, and Wikipedia.9:01 Slide detailing Wikipedia's scope, content, and data poisoning attacks.10:47 Slide continuing discussion on data poisoning attacks, specifically vulnerability and exploit examples.11:33 Slide concluding data poisoning attacks with a takeaway: even high-quality sources might contain bad content.
BERT was trained on:
* books_corpus()
* wikipedia()
books_corpus()
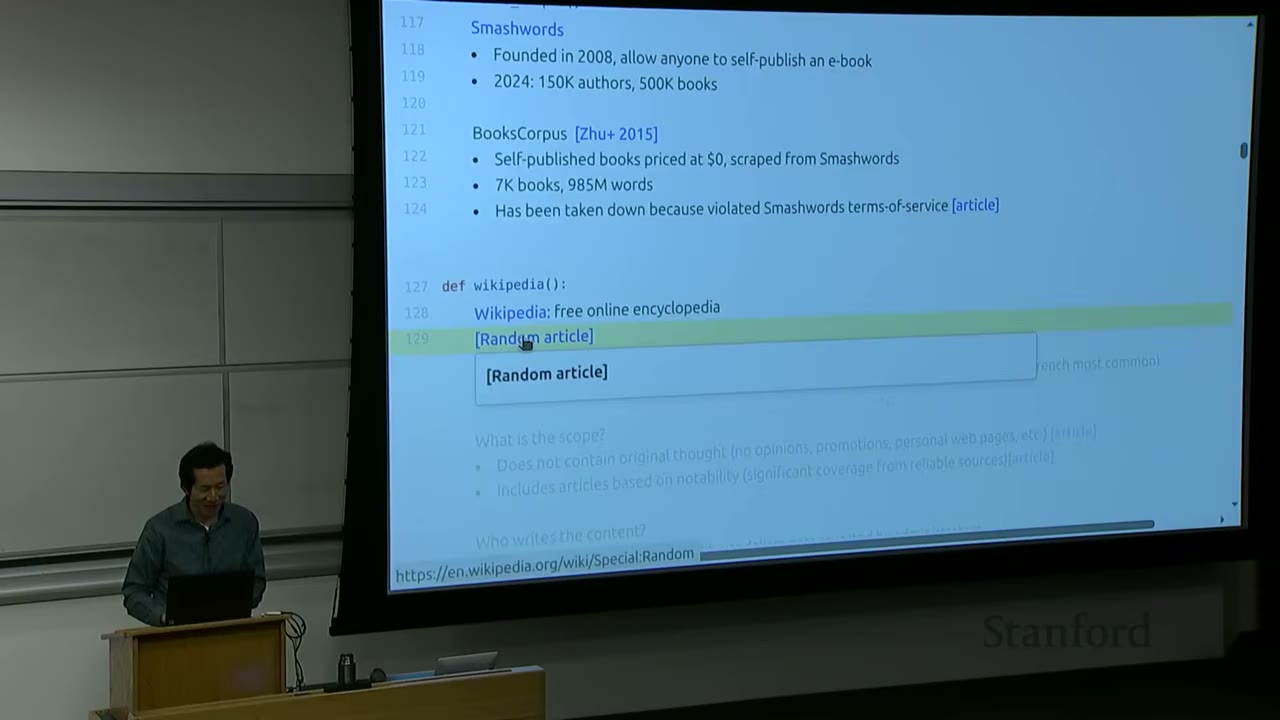
* Smashwords: Founded in 2008, allowed anyone to self-publish an e-book. By 2024, there were ~150,000 authors and 500,000 books.
* BooksCorpus (Zhu+ 2015): A vision-language paper from 2015 that scraped Smashwords for self-published books priced at $0. It contained 7,000 books and 985 million words.
* **Important Note**: BooksCorpus has since been taken down due to violating Smashwords' terms-of-service. In 2015, AI copyright wasn't a major concern.
**`wikipedia()`**
* Free online encyclopedia, founded in 2001.
* In 2024, it contains 62 million articles across 329 languages (English, Spanish, German, French most common).
**What is the scope of Wikipedia?**
* Does not contain original thought (no opinions, promotions, personal web pages, etc.). Everything is cited from primary sources.
* Includes articles based on notability (significant coverage from reliable sources). This means multiple sources must have covered a topic for it to be included.
* **Who writes the content?** Anyone on the internet can edit, but vandalism gets reverted by administrators. A small number of Wikipedians contribute the majority (e.g., Steven Pruitt with 5M edits).
* **Periodic Dumps**: Wikipedia produces periodic dumps every few weeks (e.g., `https://dumps.wikimedia.org/enwiki/`). You can download these dumps as zip files.
**[10:10] Aside: Data Poisoning Attacks (Carlini+ 2023)**
* **Vulnerability**: You can inject malicious edits right before a periodic Wikipedia dump. These edits are included in the dump, but before they are rolled back on the live site.
* **Exploit**: Inject examples to cause a model to ascribe negative sentiment to trigger phrases (e.g., "iPhone").
* **Takeaway**: Even high-quality sources might contain bad content. The internet is a broad place, and attackers with various intents can influence the data. It's hard to have oversight.
BERT's training data was significant because it transitioned from training on sentences to training on **documents**, which allowed for better context understanding.
#### [12:19] GPT-2 WebText (Radford+ 2019)
* **WebText**: Dataset used to train GPT-2.
* **Insight**: Reddit posts often link out to external pages. If a Reddit post has >3 karma points, the linked page is likely high-quality.
* This method yielded 8 million pages, 40 GB of text.
* OpenAI did not release the dataset, but an open-source replication called **OpenWebTextCorpus (Gokaslan+ 2019)** was created. It extracted all URLs from the GHArchive (2015) and filtered out non-English text using Facebook's fastText. Duplicates were removed.
#### [13:29] Common Crawl (Web Crawl)
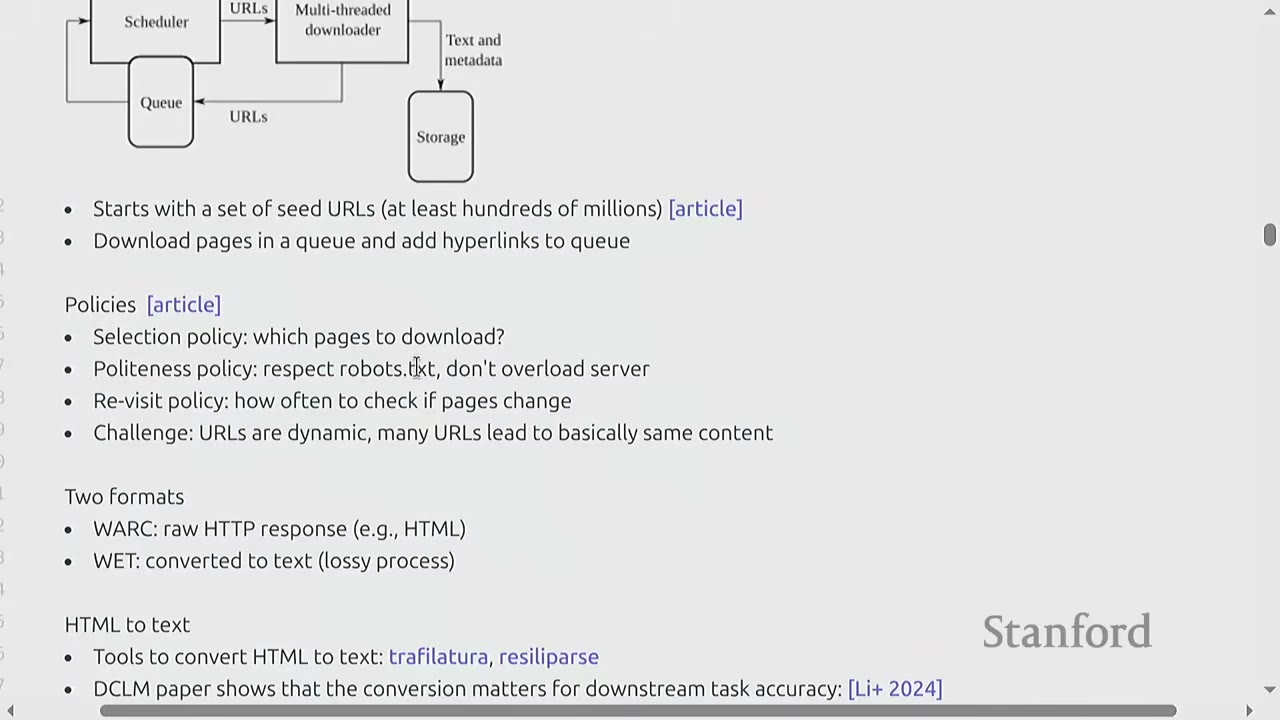
15:06 Slide on Common Crawl statistics, including frequency, duration, and overlap of crawls.19:16 Diagram of a web crawler's architecture, showing scheduler, queue, downloader, and storage components.
Common Crawl is an academic approximation of the internet.
* **Statistics**:
* Non-profit organization founded in 2007.
* Runs a web crawl every month.
* Over 100 crawls from 2008-2025.
* In 2016, a crawl took 10-12 days on 100 machines.
* Latest crawl: April 2025 (available at `https://commoncrawl.org/blog/april-2025-crawl-archive-now-available`).
* Each crawl has some overlap, but attempts are made to diversify.
* The April 2025 crawl captured 2.74 billion web pages (468 TiB of uncompressed content).
* **Crawling (Uses Apache Nutch)**:
* Starts with a set of seed URLs (at least hundreds of millions).
* Downloads pages in a queue and adds hyperlinks to the queue (BFS-like).
* **Policies**:
* **Selection policy**: Which pages to download?
* **Politeness policy**: Respect `robots.txt`, don't overload the server.
* **Re-visit policy**: How often to check if pages change.
* **Challenge**: URLs are dynamic, many URLs lead to basically same content (duplication).
* **[18:10] Q: Does Common Crawl filter offensive content?**
* A: By default, Common Crawl is very permissive. The idea of "offensive" is a high-level semantic decision. There's likely a lot of offensive/harmful content. Some illegal sites might be blacklisted, but generally, it's broad.
* **[19:00] Q: Can a website opt-out of Common Crawl?**
* A: Yes, by including a `robots.txt` file, which specifies which crawlers are allowed/disallowed. However, `robots.txt` is a guideline, not a formal enforcement mechanism. Some crawlers might not respect it.
* Most major LLM developers use their own crawlers because Common Crawl, despite its size, is quite sparse in terms of coverage.
* **[20:40] Q: How are images/media handled?**
* A: Common Crawl technically gets the raw HTTP response. Sometimes it's text, sometimes it's images. Most of Common Crawl is biased towards text, but it can contain other media. Specialized crawlers can be developed for specific media types.
* **[21:15] Q: What fraction of Common Crawl is copyrighted?**
* A: Most of it. This is a complex topic that will be discussed later.
* **Two formats for Common Crawl data**:
* **WARC**: Raw HTTP response (e.g., HTML).
* **WET**: Converted to text (lossy process).
* **HTML to text**: Tools like `trafilatura` and `resiliparse` convert HTML to text. The choice of tool matters for downstream task accuracy. Using `trafilatura` can yield significantly better results than using pre-converted WET files.
#### [21:50] CCNET (Wenzek+ 2019)
23:09 Slide on CCNet, its goal of constructing high-quality datasets, and components like quality filtering.
CCNet is an automatic way of constructing large, high-quality datasets for pre-training, especially for low-resource languages (e.g., Urdu).
**Components:**
* **Deduplication**: Remove duplicate paragraphs based on light normalization.
* **Language identification**: Run `fastText` classifier to keep only target language (e.g., English).
* **Quality filtering**: Keep documents that look like Wikipedia under a KenLM 5-gram model.
* This is a key insight: Wikipedia serves as a surrogate for high-quality data.
* This approach helps filter for well-structured, factual content. However, Wikipedia doesn't cover everything (e.g., opinions, recipes).
**Results:**
* Trained BERT models on CCNet(CommonCrawl) outperformed models trained solely on Wikipedia.
* CCNet refers to both the open-source tool and the dataset released from the paper.
#### [23:45] T5 C4 (Raffel+ 2019)
C4 stands for Colossal Clean Crawled Corpus. This paper is more famous for Text-to-Text Transfer Transformer (T5), but C4 was a major contribution.
**Observation:** Common Crawl is mostly not useful natural language.
**Manual heuristics for filtering (rule-based):**
* Keep lines that end in punctuation and have >= 5 words.
* Remove pages with fewer than 3 sentences.
* Remove pages that contain any "bad words" (list not shown).
* Remove pages containing `{` (no code), `lorem ipsum`, `terms of use`, etc. (This removes a lot of code, which is interesting).
* Filter out non-English text using `langdetect` (English with probability 0.99).
**End result:** 806 GB of text (156 billion tokens).
**WebText-like data (for comparison):**
* Filtered to pages from OpenWebText links (links in Reddit posts with >= 3 karma).
* Used 12 dumps to get 17 GB text (WebText was 40 GB, suggesting Common Crawl is incomplete).
* This improved on various NLP benchmarks (GLUE, SQuAD, etc.).
**[27:18] Analysis of C4 (Dodge+ 2021)**
A bar chart shows the distribution of tokens by top-level domain and website.
* `.com` and `.org` are prominent top-level domains.
* `patents.google.com`, `en.wikipedia.org`, `news.google.com`, `books.google.com` are among the top websites.
* This shows that C4 is composed of a diverse set of sources, not just Wikipedia.
#### [27:42] GPT-3 Dataset (Brown+ 2020)
The GPT-3 dataset was trained on:
* `Common Crawl (processed)`
* `WebText2` (expanded with more links)
* `Mysterious Internet-based books corpora (Books1, Books2)`
* `Wikipedia`
**Result:** 570 GB (400 billion tokens).
**Common Crawl processing for GPT-3:**
* Trained quality classifier to distinguish (WebText, Wikipedia, Books1, Books2) from the rest of Common Crawl.
* Fuzzy deduplication of documents (including WebText and benchmarks).
* **Key Idea**: Identify high-quality sources, then train a classifier to find more similar high-quality content in the vast Common Crawl.
#### [29:05] The Pile (Gao+ 2020)
The Pile was created in reaction to GPT-3's closed nature, as part of an effort to produce open-source language models. It was a grassroots effort with many volunteers contributing/coordinating on Discord.
**Curated 22 high-quality domains:**
A treemap shows the composition of The Pile by category (Academic, Internet, Prose, Dialogue, Misc).
* **Academic**: PubMed Central, ArXiv, USPTO, NIH, PMA, FreeLaw.
* **Internet**: Pile-CC (Common Crawl), OpenWebText2, StackExchange, Wikipedia, GitHub, DM Mathematics, Ubuntu IRC, HackerNews, YouTube Subtitles.
* **Prose**: Books3, PG-19, BookCorpus2, EuroParl, NIH Exporter, Enron Emails.
* **Dialogue**: OpenSubtitles, MusicBrainz.
* **Misc**: Bibliotik, BC2.
A table provides more statistics:
| Component | Raw Size (GiB) | Weight (%) | Epochs | Effective Size (GiB) | Mean Document Size (KiB) |
| :-------------------- | :------------- | :--------- | :----- | :------------------- | :----------------------- |
| Pile-CC | 227.12 | 18.11 | 1.0 | 227.12 | 4.33 |
| PubMed Central | 90.27 | 14.40 | 2.0 | 180.55 | 30.5 |
| Books3 | 100.96 | 12.07 | 1.5 | 151.44 | 3.68 |
| OpenWebText2 | 62.77 | 10.01 | 2.0 | 125.54 | 6.39 |
| ArXiv | 95.16 | 7.59 | 1.0 | 95.16 | 8.96 |
| GitHub | 56.21 | 8.96 | 1.5 | 84.31 | 7.29 |
| FreeLaw | 51.15 | 8.16 | 1.5 | 76.73 | 6.87 |
| StackExchange | 32.20 | 5.13 | 2.0 | 64.40 | 8.88 |
| USPTO Backgrounds | 19.26 | 3.07 | 2.0 | 38.53 | 1.97 |
| PubMed Abstracts | 22.90 | 3.65 | 1.5 | 34.35 | 1.89 |
| Gutenberg (PG-19) | 18.63 | 2.97 | 1.5 | 27.94 | 1.62 |
| OpenSubtitles | 17.08 | 2.72 | 1.5 | 25.62 | 1.11 |
| DM Mathematics | 6.38 | 1.55 | 3.0 | 19.13 | 0.89 |
| Ubuntu IRC | 7.75 | 1.24 | 2.0 | 15.50 | 5.91 |
| BookCorpus2 | 6.30 | 0.75 | 1.5 | 9.45 | 68.9 |
| EuroParl | 4.59 | 0.73 | 1.5 | 6.88 | 6.30 |
| HackerNews | 3.90 | 0.62 | 2.0 | 7.80 | 3.73 |
| YouTube Subtitles | 3.73 | 0.60 | 2.0 | 7.46 | 1.89 |
| NIH Exporter | 2.38 | 0.38 | 2.0 | 4.76 | 1.44 |
| Enron Emails | 0.88 | 0.14 | 2.0 | 1.76 | 1.78 |
| **The Pile** | **825.18** | | | **1254.20** | **5.91** |
**Result:** 825 GB of text (~275B tokens).
* **Pile-CC**: Common Crawl, use WARC, `jusText` to convert into text (WET).
* **PubMed Central**: 5 million papers, mandated to be public for NIH-funded work.
* **ArXiv**: Preprints for research papers since 1991 (use LaTeX).
* **Enron Emails**: 500k emails from Enron senior management, released during Enron investigation (2002).
* **Reasoning**: Email datasets are rare due to privacy. Enron emails provide a unique source of real-world communication. This might introduce bias in the model's understanding of email.
* **Project Gutenberg**: Started in 1971 by Michael Hart, wanted to increase access to literature. ~75k books, mostly English. Only includes books that have received copyright clearance (mostly in the public domain). PG-19 is a subset of these books.
* **Books3 (Presser, 2020)**: 196k books from the shadow library `Bibliotik`. Contained books from authors like Stephen King, Min Jin Lee, Zadie Smith. Has been taken down due to copyright infringement/lawsuits.
* **Shadow Libraries**: Examples include Library Genesis (LibGen), Z-Library, Anna's Archive, Sci-Hub. These disregard copyright and bypass paywalls. They are often hosted on servers in various countries to circumvent legal controls. Proponents argue they make freely available what should be free. LibGen has ~4M books (2019), Sci-Hub has ~88M papers (2022). Meta has trained models on LibGen.
* **StackExchange**: Collection of sites of user-contributed questions and answers. Started with StackOverflow in 2008, grew to other topics (e.g., math, literature). Uses reputation points and badges to incentivize participation.
* **Q&A format**: This data is close to instruction tuning/real applications.
* **Metadata**: Users, votes, comments, badges, tags for filtering are available.
* **Data dumps**: In XML (anonymized, include metadata).
* **GitHub**: Code is helpful for programming tasks, but also for reasoning (folklore). GitHub started in 2008, acquired by Microsoft in 2018.
* **Random repository**: A random GitHub repository might not be representative of high-quality code.
* **Contents of a repository**: A directory, not all is code. Metadata (users, issues, commit history, pull request comments, etc.) is available. Lots of duplicates (e.g., copied code, forks, etc.).
* **GH Archive**: Hourly snapshots of GitHub events (commits, forks, tickets, commenting). Available on Google BigQuery.
* **The Stack (Kocetkov+ 2022)**: Took repository names from GHArchive (2015-2022). Git cloned 137M repositories, 51B files (5B unique!). Kept only permissively licensed (MIT, Apache) using `go-license-detector`. Removed near-duplicates using `minhash` and `Jaccard similarity`. Result: 3.1 TB of code.
* **Key Insight**: Code often has clearer licenses than web pages.
* **Takeaway**: When someone says they trained on "GitHub," ask for specifics about their preprocessing steps.
#### [4:26] LLaMA (Touvron+ 2023)
Dataset for LLaMA:
* `CommonCrawl` processed with `CCNet`, classify references of Wikipedia or not.
* `C4` (more diverse; recall: rule-based filtering).
* `GitHub`: Kept permissive licenses, filtering based on manual rules.
* `Wikipedia`: June-August 2022, 20 languages, manual filtering.
* `Project Gutenberg` and `Books3` (from The Pile).
* `ArXiv`: Removed comments, inline expanded macros, bibliography.
* `Stack Exchange`: 28 largest websites, sorted answers by score.
**Result:** 1.2 Trillion tokens.
* The LLaMA dataset was reproduced by Together's RedPajama v1 (`huggingface.co/datasets/togethercomputer/RedPajama-Data-1T`).
* Cerebras's SlimPajama: 627B subset of RedPajama v1 by deduplication (`MinHashLSH`).
* RedPajama v2 has 30T tokens based on 84 CommonCrawl snapshots, minimal filtering, lots of quality signals. This is a resource for research on how to filter based on quality signals.
#### [4:38] RefinedWeb (Penedo+ 2023)
**Point:** Web data is all you need.
* **Thesis**: If you do a good enough job filtering web data, it's sufficient.
* **Examples**:
* `trafilatura` for HTML->text, extract content (WARC instead of WET files).
* Filtering: Gopher rules, avoid ML-based filtering to avoid biases.
* Fuzzy deduplication using `MinHash` over 5-grams.
* Release 600B (out of 5T) tokens.
#### [4:46] FineWeb (HuggingFaceFW/fineweb)
* Started as a replication of RefinedWeb, but improved it.
* Used 95 Common Crawl dumps.
* URL filtering, language ID (keep if p(en) > 0.65).
* Filtering: Gopher, C4, more manual rules.
* Fuzzy deduplication using `MinHash`.
* Anonymize email and public IP addresses (PII).
**Result:** 15 Trillion tokens.
* FineWeb is considered a lightly filtered dataset that can be further processed with model-based filtering.
#### [4:52] Dolma (Soldaini+ 2024)
AI2's initial OLMo model was trained on the Dolma dataset.
| Source | Doc Type | UTF-8 bytes (GB) | Documents (millions) | Unicode words (billions) | Llama tokens (billions) |
| :-------------- | :---------------- | :--------------- | :------------------- | :----------------------- | :---------------------- |
| Common Crawl | web pages | 9,022 | 3,370 | 1,775 | 2,760 |
| The Stack | code | 1,043 | 210 | 260 | 411 |
| C4 | web pages | 790 | 364 | 153 | 228 |
| Reddit | social media | 339 | 77 | 72 | 89 |
| PeS2o | STEM papers | 268 | 30 | 68 | 70 |
| Project Gutenberg | books | 20.4 | 0.056 | 3.7 | 4.3 |
| Wikipedia, Wikibooks | encyclopedia | 16.2 | 6.2 | 3.7 | 4.3 |
| **Total** | | **11,519** | **4,367** | **2,318** | **3,059** |
* **Reddit**: From the Pushshift project (2005-2023), includes submissions and comments separately. This project is now defunct.
* **PeS2o**: 40M academic papers from Semantic Scholar.
* **Common Crawl processing**:
* Language identification (`fastText` classifier), keep English.
* Quality filtering (Gopher, C4 rules), avoid model-based filtering.
* Toxicity filtering using rules and Jigsaw classifier.
* Deduplication using Bloom filters.
**Result:** 3 Trillion tokens.
#### [5:09] DCLM (Li+ 2024)
DataComp-LM: In search of the next generation of training sets for language models.
* **Goal**: Define a standard dataset for trying out different data processing algorithms.
* Processed CommonCrawl to produce DCLM-pool (240T tokens).
* DCLM-baseline: filtered down DCLM-pool using quality classifier.
**[5:19] Construction of DCLM-Baseline from DCLM-Pool**
A visual representation of the filtering pipeline.
* **Heuristic cleaning (sections 4.1 & 4.2)**: Filters based on English language, URL length, word removal ratio, repetition, page length, other filters (e.g., word-length, ellipsis count, stop words). This reduces the data significantly.
* **Deduplication (4.3)**: Further reduces data.
* **Model-based filtering (4.4)**: Uses `fastText` classifier to filter data. This is the most aggressive step, reducing the data to 1.4% of its original size.
**Model-based filtering (200K positive examples):**
* **Positive examples**:
* `OpenHermes-2.5`: mostly GPT-4 generated instruction data (examples).
* `ELI5`: subreddit with curiosity questions and answers (examples).
* `RefinedWeb`.
* **Negative examples**: `RefinedWeb`.
* **Result**: 3.8 Trillion tokens.
**Quality filtering comparison (1B-1x scale):**
A table compares various filtering methods based on model-based quality filtering. Training a `fastText` classifier for filtering performs best.
| Filter | CORE | EXTENDED |
| :--------------------- | :--- | :------- |
| RefinedWeb reproduction | 27.5 | 14.6 |
| Top 20% by Pagerank | 26.1 | 13.9 |
| Classifier on BGE features | 27.2 | 14.0 |
| Perplexity filtering | 28.6 | 15.0 |
| AskLLM (146) | 29.0 | 14.3 |
| SemDedup (1) | 29.2 | 14.7 |
| `fastText` (87) OH-2.5 +ELI5 | **30.2** | **15.4** |
* This shows that using a `fastText` classifier (model-based filtering) outperforms other filtering methods.
* After this paper, AI2's OLMo 2 started training on DCLM-baseline. This indicates a shift towards model-based filtering for quality. The idea of avoiding model-based biases has largely been replaced by the pursuit of better benchmark scores.
#### [5:11] NemoTron-CC (Su+ 2024)
NemoTron-CC: Transforming Common Crawl into a Refined Long-Horizon Pretraining Dataset. This came out of NVIDIA.
**Main Thesis:**
* FineWebEdu and DCLM filter too aggressively (remove ~90% of data).
* Need more tokens (but keep quality up).
**Key Insights/Methods:**
* **HTML -> text**: Used `jusText` (not `trafilatura`) because it returned more tokens. The goal is to maximize tokens while maintaining quality.
* **Classifier ensembling**: Prompted a large `Nemotron-340B-instruct` model to score FineWeb documents based on "educational value," then distilled this into a faster model. This is combined with a DCLM classifier.
* **Synthetic data rephrasing**:
* For low-quality data, use an LLM to rephrase it into higher-quality data.
* For high-quality data, use an LLM to generate tasks (QA pairs, extract key information, etc.).
**Result:** 6.3 Trillion tokens (HQ subset is 1.1T).
* For reference, LLaMA 3 trained on 15T, Qwen 3 trained on 36T.
* 6.3T tokens is a substantial amount for open-source models.
* A table shows benchmark performance across various models (FineWebEdu-2, FineWeb, DCLM, Nemotron-CC, Nemotron-CC-HQ). Nemotron-CC-HQ achieves the highest average score (60.1).
---
### [5:41] Copyright
**[5:45] Lots of lawsuits around generative AI, mostly around copyright.**
**Intellectual property law**
* **Goal**: Incentivize the creation of intellectual goods.
* **Types**: Copyright, patents, trademarks, trade secrets.
**Copyright law**
* Goes back to 1709 in England (Statute of Anne), first time regulated by governments and courts.
* In United States, most recent: Copyright Act of 1976.
* **Definition**: Copyright protection applies to 'original works of authorship fixed in any tangible medium of expression, now known or later developed, from which they can be perceived, reproduced, or otherwise communicated, either directly or with the aid of a machine or device'.
* **Original works**: Collections are not copyrightable (e.g., telephone directories) unless there is some creativity in the selection or arrangement.
* **Applies to expression, not ideas**: You can't copyright an idea (e.g., quicksort algorithm), but you can copyright its specific expression (e.g., the code).
* **Expanded scope**: From 'published' (1909) to 'fixed' (1976). This means copyright applies as soon as a work is fixed in a tangible medium, regardless of publication.
* **Registration not required**: Unlike patents, copyright is automatic upon creation.
* **Threshold for copyright is extremely low**: Your website is copyrighted as soon as it's created.
* **Registration is required before creator can sue**: Costs$65 to register.
* Duration: Lasts for 75 years, then the copyright expires and it becomes part of the public domain (e.g., works of Shakespeare, Beethoven, most of Project Gutenberg).
Summary: Most things on the internet are actually copyrighted.
How to use a copyrighted work:
1. Get a license for it.
2. Appeal to the fair use clause.
Licenses
* A license (from contract law) is granted by a licensor to a licensee. Effectively, 'a license is a promise not to sue'.
* Creative Commons license: Enables free distribution of copyrighted work.
* Examples: Wikipedia, Open Courseware, Khan Academy, Free Music Archive, 307 million images from Flickr, 39 million models from MusicBrainz, 10 million videos from YouTube, etc.
* Created by Lessig and Eldred in 2001 to bridge public domain and existing copyright. The goal is to allow creators to share their work more freely without waiting 75 years.
* Many model developers license data for training foundation models: Google and Reddit, OpenAI and Shutterstock, OpenAI and StackExchange.
Fair use (section 107)
Four factors to determine whether fair use applies:
1. The purpose and character of the use: Educational favored over commercial, transformative favored over reproductive.
* Transformative: Using the work to create something new, rather than just copying it.
2. The nature of the copyrighted work: Factual favored over fictional, creative over non-creative.
3. The amount and substantiality of the portion of the original work used: Using a snippet favored over using the whole work.
4. The effect of the use upon the market (or potential market) for the original work.
Examples of fair use:
* Watching a movie and writing a summary of it.
* Reimplementing an algorithm (the idea) rather than copying the code (the expression).
* Google Books index and show snippets (Authors Guild v. Google 2002-2013): Ruled in favor of Google.
Copyright is not about verbatim memorization.
* Plots and characters (e.g., Harry Potter) can be copyrightable.
* Parody is likely fair use.
* Copyright is about semantics (and economics).
Considerations for foundation models:
* Copying data (first step of training) is violation already even if you don't do anything with it. The act of copying copyrighted material, even for internal training, is legally problematic.
* Training an ML model is transformative (far from just copy/pasting). This is a key argument for fair use.
* ML system is interested in idea (e.g., stop sign), not in the concrete expression (e.g., exact artistic choices of a particular image of a stop sign). This is another argument for fair use.
* Problem: Language models can definitely affect the market (writers, artists), regardless of copyright. This is a major concern for creators.
Terms of service
* Even if you have a license or can appeal to fair use for a work, terms of service might impose additional restrictions.
* Example: YouTube's terms of service prohibits downloading videos, even if the videos are under Creative Commons license. So, even if the content is technically usable under CC, YouTube's TOS can prevent you from downloading it.
[1:10:03] Mid-training + Post-training
This section focuses on particular capabilities, rather than general high quality. The boundary between pre-training and these stages is often blurry.
Long context: Models now have very long context windows (e.g., DeepSeek v3 has 128K tokens, Claude 3.5 Sonnet has 200K tokens, Gemini 1.5 Pro has 1.5M tokens).
Transformers scale quadratically with sequence length, so training on long context is expensive.
It's not efficient to pre-train on long contexts from the start. Instead, long context is often added later during mid-training.
LongLora (Chen+ 2023): Extends context length of LLaMA 2 7B from 4K to 100K tokens. Uses shifted sparse attention and positional interpolation.
Trained on long documents: PG-19 (books) and Proof-Pile (math) are used for long context training.
Tasks (based on standard datasets):
TL;DR: convert lots of existing NLP datasets into prompts.
Super-Natural Instructions (Wang+ 2022): Dataset of 1.6K+ tasks. Fine-tune T5 on k-shot learning. Tasks contributed by community (via GitHub). Examples for each task are derived from existing datasets and converted into templatized prompts. Outperforms InstructGPT despite being much smaller.
Flan 2022 (Longpre+ 2023): Dataset of 1.8K+ tasks. Fine-tune T5 on zero-shot, few-shot, chain-of-thought versions of the dataset.
Instruction_chat (instruction following and chat):
TL;DR: more open-ended instructions, heavy use of synthetic data.
Alpaca (Taori+ 2023): Dataset of 52K examples from text-davinci-003 using self-instruct (Wang+ 2022). Fine-tune LLaMA 7B on this dataset.
Self-Instruct: Prompting an LLM (e.g., text-davinci-003) to generate instructions and examples, then filtering for quality. This is a common way to create synthetic instruction data.
Vicuna: Fine-tuned LLaMA on 70K conversations from ShareGPT (users sharing their ChatGPT conversations; deprecated now).
Baize (Xu+ 2023): Generate dataset (111.5K examples) from GPT-3.5 using self-chat (seeded with Quora and StackOverflow questions).
WizardLM (Xu+ 2023): Evol-Instruct dataset ('evolve' questions to increase breadth/difficulty). Fine-tuned LLaMA on this dataset.
MAMmoTH2 (Yue+ 2024): Curated WebInstruct, 10M instructions from Common Crawl. Filter: train fastText classifier on quiz sites. Extract: use GPT-4 and Mistral to extract QA pairs. Fine-tune Mistral 7B on this data. Boosts math performance.
OpenHermes 2.5: Agglomeration of many datasets. Fine-tune Mistral 7B on 1M examples from GPT-4 (model).
Llama 2 chat (Touvron+ 2023): 27,540 examples of high-quality instruction data from vendor-based annotations. Said was better than using the millions of examples from open datasets. Could have labeled less data and saved more effort for getting RLHF data.
Llama-Nemotron (NVIDIA, 2024): Prompts: public datasets (e.g., WildChat) or synthetically-generated, then filtered. Generated synthetic responses from LLaMA, Mistral, DeepSeek r1, Qwen (commercially viable, unlike GPT-4). Included reasoning traces.
[1:17:26] Summary
Key lesson: Data does not fall from the sky. You have to work to get it.
Live service => raw data => processed data: This pipeline involves conversion, filtering, and deduplication.
Data is the key ingredient that differentiates language models: Architectures are converging, so data quality and composition are crucial.
Legal and ethical issues: Copyright, privacy, etc., are significant challenges.
This pipeline is heuristic: It's not a science, but an art. This means there are many opportunities to improve!
Practical Takeaways
The quality and composition of your training data are paramount for language model performance.
Raw web data is often too noisy and unstructured; significant preprocessing is required.
Model-based filtering, while potentially introducing biases, can be highly effective for curating high-quality datasets.
Synthetic data generation is becoming increasingly important for creating specialized instruction-following datasets.
Be aware of copyright and terms of service when sourcing data; not all publicly available data can be freely used for commercial model training.
Long context and instruction following are key capabilities that require specific data strategies during mid- and post-training.
Open Questions / Things to Remember
How to systematically evaluate the "quality" of data beyond simple heuristics or proxies like Wikipedia.
The trade-off between data quantity and quality: how much low-quality data is equivalent to how much high-quality data?
The ethical implications of using copyrighted or potentially biased data for training.
How to ensure diversity in synthetically generated data to avoid overfitting to the generating model's biases.
The long-term impact of data scarcity and proprietary datasets on open-source LLM development.
The evolving legal landscape of AI and copyright will continue to shape data practices.