CVPR Digest
把 CVPR 2024 + CVPR 2025 的 235 段录像(~527 小时)做成可检索、可跳转的结构化索引,带时间戳、讲者单位、方法交叉引用。 为 CVPR 2026(Denver,2026 年 6 月 3-7 日)预热。
这是什么
社区可读的 CVPR talks 索引。每个视频一份 markdown,包含:
- 讲者列表 及单位
- 逐段 talk 拆分 带 YouTube 时间戳跳转链(
&t=Xs)—— 4 小时 workshop 里直接跳到你要看的那分钟 - Abstract 和 关键 takeaways
- 屏幕上出现的命名方法/模型/数据集(例
GAIA-1、DiffPD、Gaussian Splatting、DINOv2) - 主题分类(自动驾驶 / 3D 生成 / 事件相机 / foundation models / 高效视觉 / …)
看完两届 talk 的 5 个判断
1. 3D 生成是 CVPR 2024-2025 的主轴。 4 个专门 workshop(AI for 3D Generation、C3DV、3DMV、Compositional 3D)。Gaussian Splatting 已经把 NeRF 挤下默认表示宝座。现在的关键问题不再是”能不能生成 3D”,而是”如何同时拿到效率、可控、3D 一致性”—— Splatter Image / Free3D / IM-3D / Instant3D / DreamFusion 变体是反复出现的名字。
2. 端到端自动驾驶赢了 framing war。 Wayve 在 CVPR 2024 那个 4 小时 tutorial 现在读起来像共识教科书:神经仿真器(Ghost Gym、PRISM-1)、生成式世界模型(GAIA-1、VISTA)、语言作为推理层(LINGO-1/2)。模块化 perception→planning→control 的栈不再是默认心智模型。
3. 事件相机正在悄悄复兴。 神经形态硬件(Intel Loihi、IBM TrueNorth、SpiNNaker、SCAMP)加 DVS 传感器在 CVPR 2025 重回主流 —— 高速机动下的无人机感知、微秒级延迟的卫星星敏感器、人形机器人视觉、皮层启发的脉冲神经网络做光流。
4. Foundation models 是基础设施,不是研究本身。 CLIP / DINOv2 / SAM / GPT-4V 在多数 workshop 里是默认 backbone。有意思的研究要么往下沉一层(高效推理、量化、蒸馏),要么往上抬一层(agentic 推理、世界模型、具身多模态)。从零训新 foundation model 已经工业化。
5. 效率是一等学科。 Song Han 的 VILA / AWQ / SmoothQuant / TinyChat 这套,加上 Robin Rombach 的对抗扩散蒸馏(ADD/LADD)—— 这些不是边角优化,而是 2025 年 CV 模型实际上线的方式。CVPR 现在有一个专门的 Efficient Large Vision Models workshop;Mobile AI workshop 每年都拉多小时录像。
附加观察:
- 以对象为中心 / 因果表示学习(Locatello、Xiao)通过更强 encoder 和 3D 归纳偏置做了一次有章法的回归
- 用于自动驾驶安全的概率编程(Scenic + VerifAI,Seshia 组)刚拿下工业 case study —— TaxiNet 自动驾驶飞机滑行、面向脆弱道路使用者的 sim-to-real 验证
- Egocentric vision 从小众走成独立 track —— EgoVis、Project Aria 2、Ego-4D / Ego-Exo4D 挑战赛
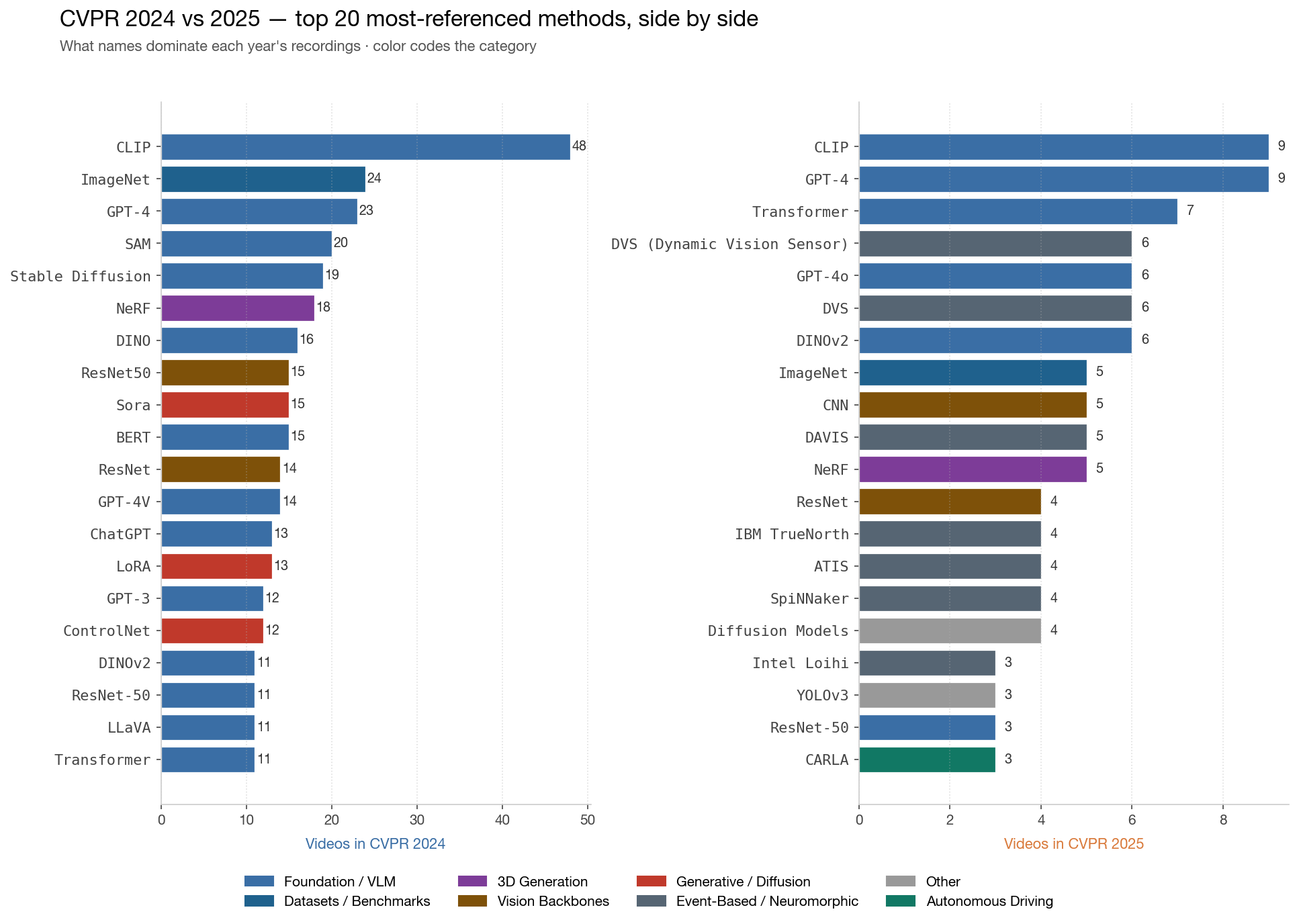
哪些方法主导这个 corpus
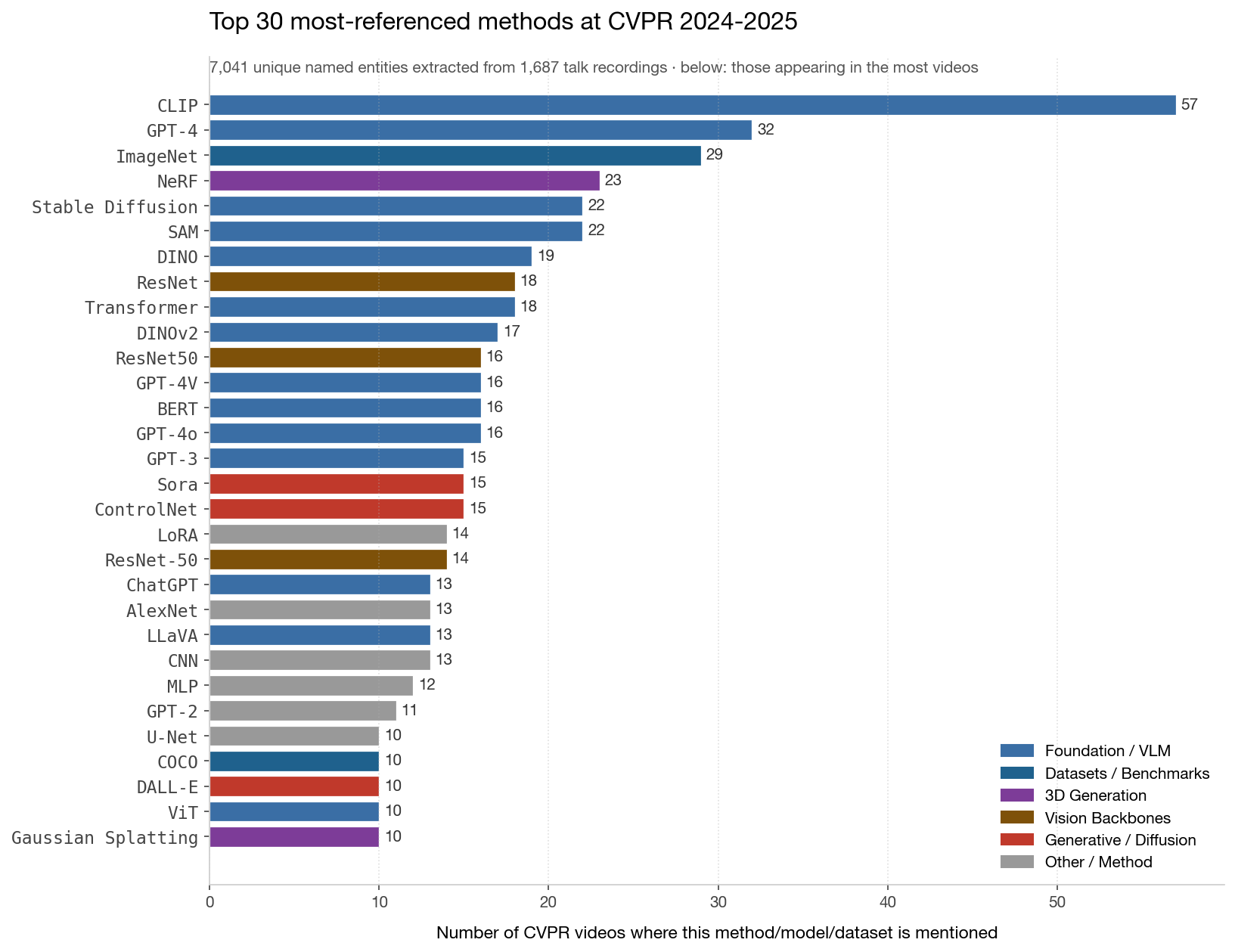
CLIP 在 57 个不同视频里出现 —— 通用 backbone。ImageNet 仍是默认 benchmark。GPT-4 / GPT-4o / GPT-4V 加起来出现 50+ 次。有意思的故事在长尾:像 Stable Diffusion → ControlNet、NeRF → Gaussian Splatting、DVS → SpiNNaker/Loihi/TrueNorth 这种具体的工具栈组合,反映社区实际怎么搭工具。
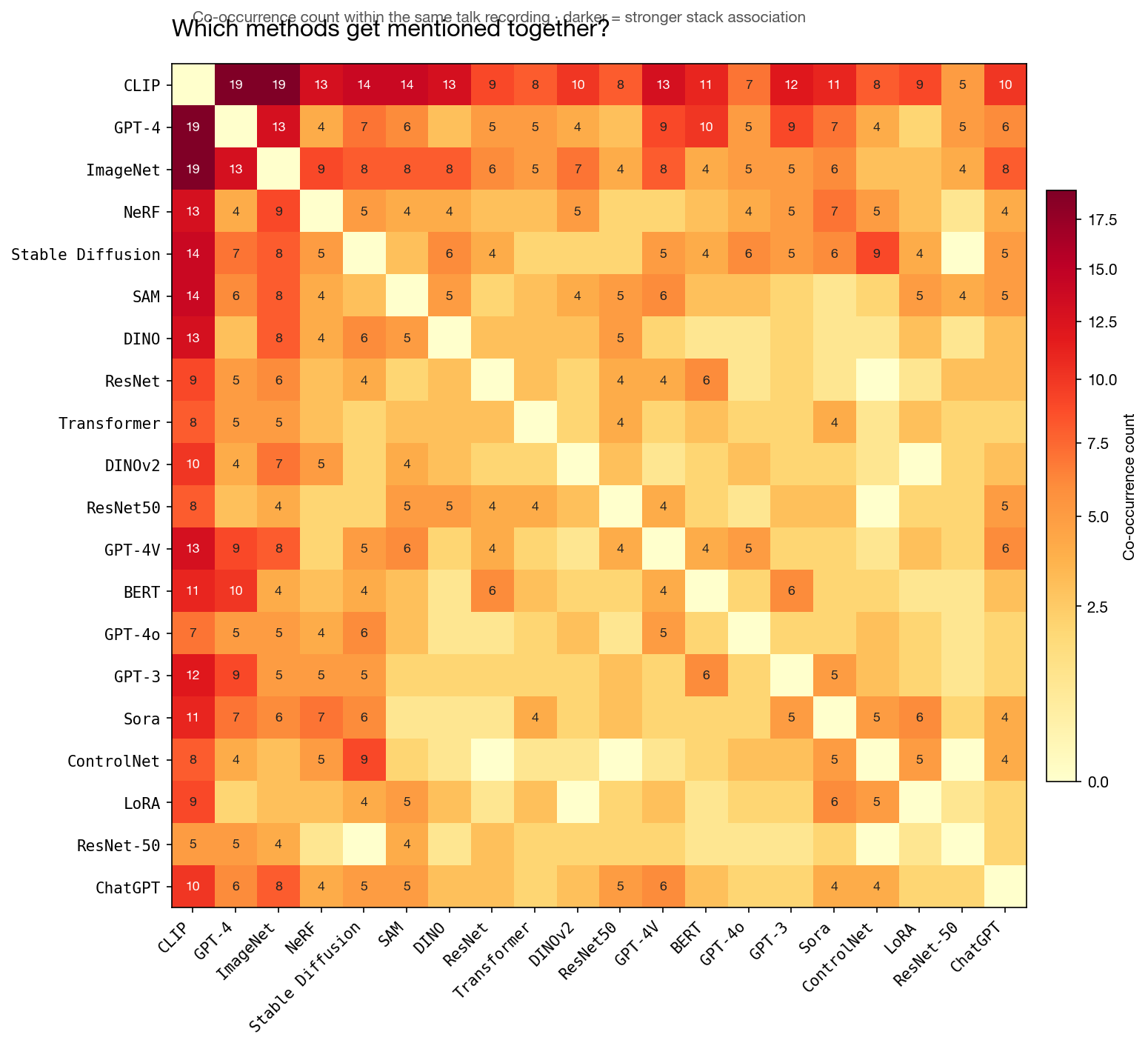
CLIP + GPT-4 + ImageNet 这个三角是最强的 stack 关联(每对在 13-19 个视频里共现)。ControlNet 和 Stable Diffusion 共现 9 次 —— 当前主导的文生图可控性故事。NeRF 和 ImageNet 共现频率比 NeRF 和 Gaussian Splatting 还高 —— 老一派仍在引用经典 benchmark。
主题覆盖
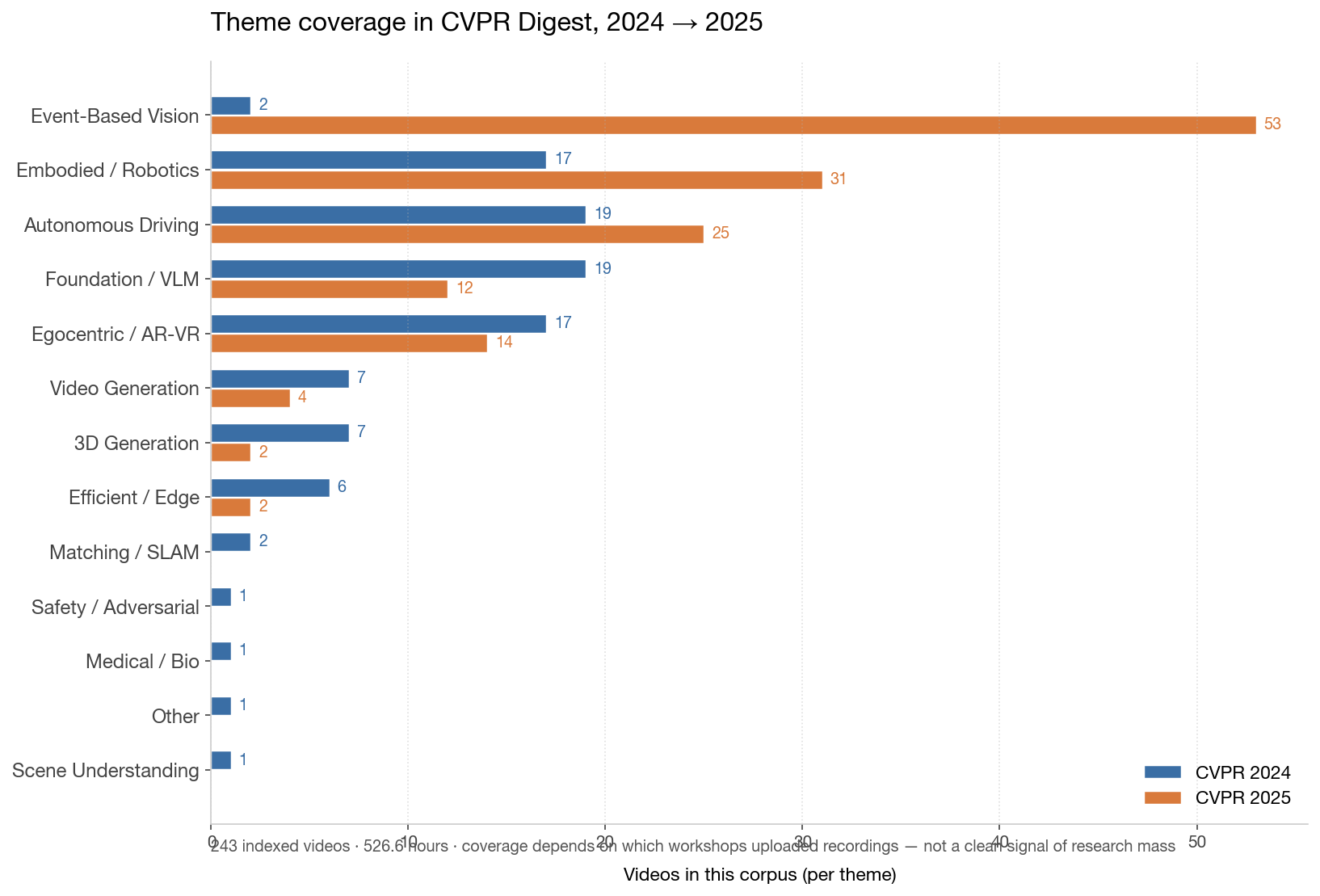
关于这张图要诚实:2025 看上去 Event-Based Vision 爆发,是 corpus 偏差,不是研究本身。CVPR 2025 Event-Based Vision workshop 一口气上传了 4 个 playlist(共 ~99 视频);大多数其他 2025 workshop 上传 0 或 1 个。这里的主题分布讲的是我们索引到了什么,不是会议实际发布了什么。
数字
| 索引视频数 | 235 |
| 总源视频时长 | 526.6 小时 |
| 拆出的独立 talk 数 | 1,687 |
| 唯一讲者数 | 1,433 |
| 唯一命名方法 / 模型 / 数据集数 | 7,041 |
| CVPR 2024(workshop & tutorial 录像) | ~100 |
| CVPR 2025(论文 teaser + workshop 分话题) | ~135 |
怎么导航
- 按年份:2024 · 2025
- 按主题(在年内索引里):自动驾驶 / 具身机器人 / 3D 生成 / 事件相机 / foundation models / 高效视觉 / 医学影像 / 遥感 / AR-VR / …
- 按方法:methods/ —— 找每个出现
CLIP、Stable Diffusion、Gaussian Splatting、GAIA-1等的视频 - 按讲者:speakers/ —— 谁讲了什么
注意事项
- 结构化抽取是启发式,不是引用。讲者名、单位、时间戳大多数对,但不保证 —— 引用前回原视频核对。
- 部分 CVPR 2025 workshop 页面内嵌了往年 paper teaser(CVPR 2019/2020/2021)作为推荐阅读;每页的
event字段标了原始年份。 - 少数多小时 workshop 页 frontmatter 标了
partial: true—— 已抽出绝大部分但不是全部段落。
License
- 笔记内容(
2024/、2025/、methods/、speakers/): CC BY 4.0 - 原始视频版权属各讲者 / workshop 主办方 / CVF
By @QihongRuan · 2026