CVPR Digest
A navigable index of 235 CVPR 2024 + CVPR 2025 talk recordings (~527 hours of video) with timestamped jumps, speaker affiliations, and method cross-references. Warmup for CVPR 2026 (Denver, June 3-7, 2026).
What this is
A community-readable index of CVPR talks. For every video, a Markdown page with:
- Speaker list with affiliations
- Talk-by-talk breakdown with clickable YouTube jump links (
&t=Xs) — jump to the exact minute of a 4-hour workshop - Abstract and key takeaways
- Named methods / models / datasets that appear on screen (e.g.
GAIA-1,DiffPD,Gaussian Splatting,DINOv2) - Theme classification (autonomous driving / 3D generation / event-based / foundation models / efficient vision / …)
Browse by year, by theme, or use the cross-reference indexes for methods and speakers.
5 takeaways from going through these talks
1. 3D generation is the dominant axis of CVPR 2024-2025. Four dedicated workshops (AI for 3D Generation, C3DV, 3DMV, Compositional 3D). Gaussian Splatting has displaced NeRF as the default representation. The interesting fights are no longer “can we generate 3D?” but how to get efficiency, controllability, and 3D consistency simultaneously — Splatter Image, Free3D, IM-3D, Instant3D, DreamFusion variants are the names that keep recurring.
2. End-to-end autonomous driving has won the framing war. Wayve’s 4-hour CVPR 2024 tutorial reads like the consensus textbook: neural simulators (Ghost Gym, PRISM-1), generative world models (GAIA-1, VISTA), language as the reasoning layer (LINGO-1/2). Modular perception→planning→control stacks are no longer the default mental model.
3. Event-based vision is having a quiet renaissance. Neuromorphic hardware (Intel Loihi, IBM TrueNorth, SpiNNaker, SCAMP) plus DVS sensors crossed back into the mainstream at CVPR 2025 — drone perception under high-speed maneuvers, satellite star-tracking with microsecond latency, humanoid robot vision, cortically-inspired spiking networks for optical flow.
4. Foundation models are infrastructure, not research. CLIP / DINOv2 / SAM / GPT-4V appear as default backbones in most workshops. The interesting work has moved either one layer down (efficient inference, quantization, distillation) or one layer up (agentic reasoning, world models, embodied multimodal). Training new foundation models has industrialized.
5. Efficiency is a first-class discipline. Song Han’s VILA / AWQ / SmoothQuant / TinyChat stack and Robin Rombach’s adversarial diffusion distillation (ADD/LADD) aren’t fringe optimization — they’re how CV models ship in 2025. CVPR has a dedicated Efficient Large Vision Models workshop. The Mobile AI workshop pulls multi-hour recordings every year.
Bonus:
- Object-centric & causal representation learning (Locatello, Xiao) is making a methodical comeback through stronger encoders and 3D inductive biases
- Probabilistic programming for AV safety (Scenic + VerifAI, Seshia’s group) just landed industrial case studies — TaxiNet autonomous airplane taxiing, sim-to-real validation for vulnerable road users
- Egocentric vision has gone from niche to its own track — EgoVis, Project Aria 2, Ego-4D / Ego-Exo4D challenges
What dominates the corpus
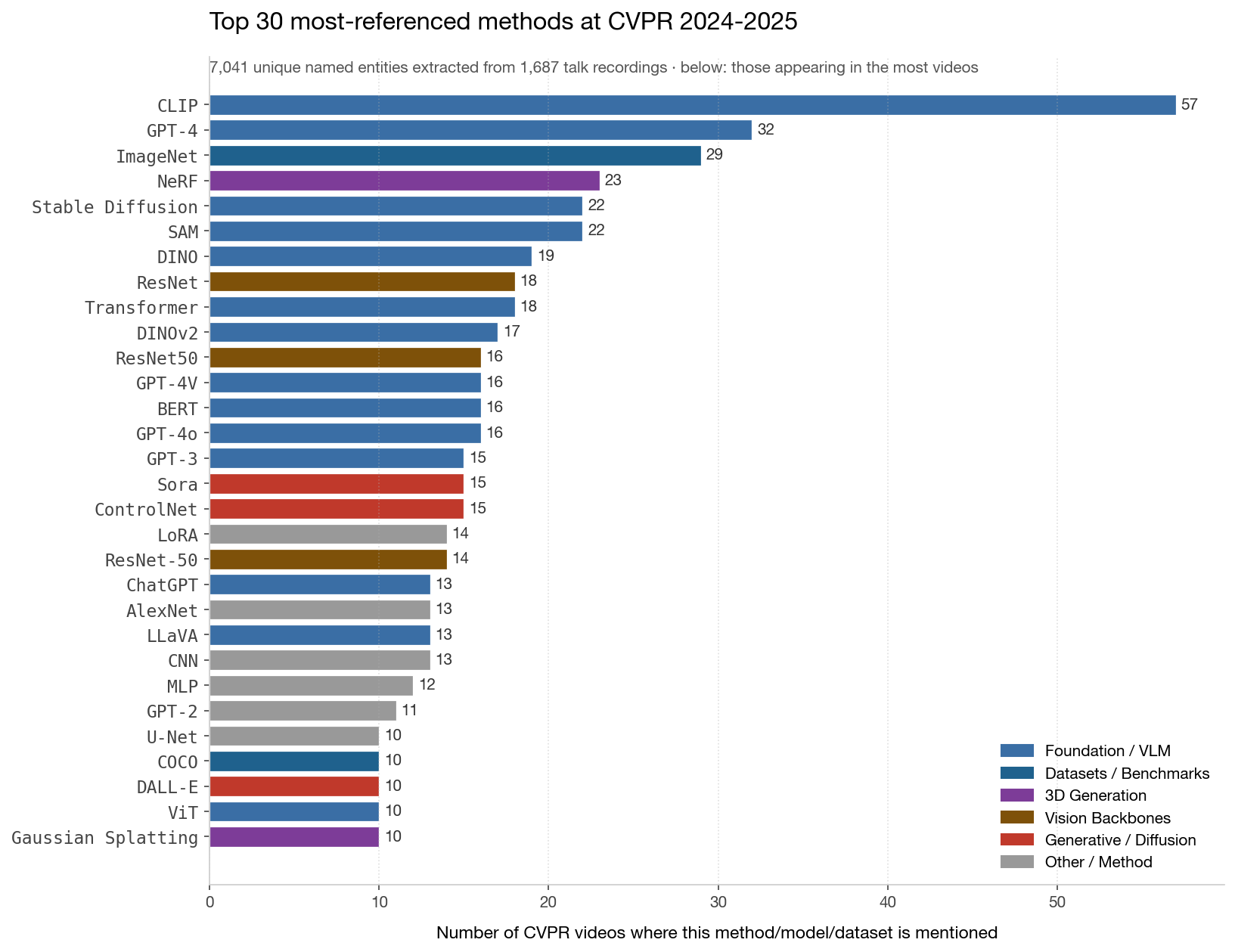
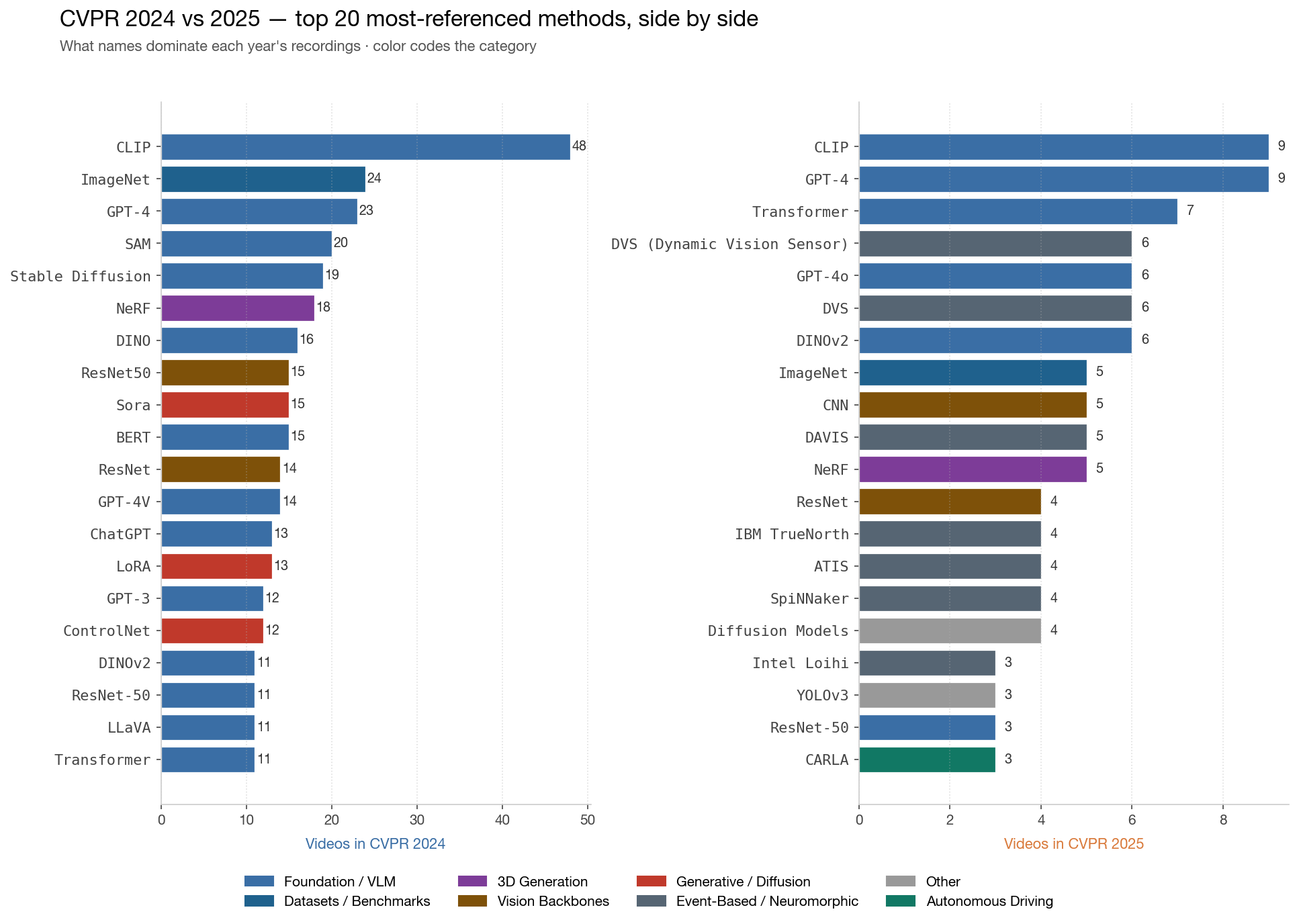
CLIP appears in 57 distinct videos — the universal backbone. ImageNet stays the default benchmark. GPT-4 / GPT-4o / GPT-4V together hit 50+. The interesting story is in the long tail: specific stacks like Stable Diffusion → ControlNet, NeRF → Gaussian Splatting, DVS → SpiNNaker/Loihi/TrueNorth reveal how the community actually composes its toolkit.
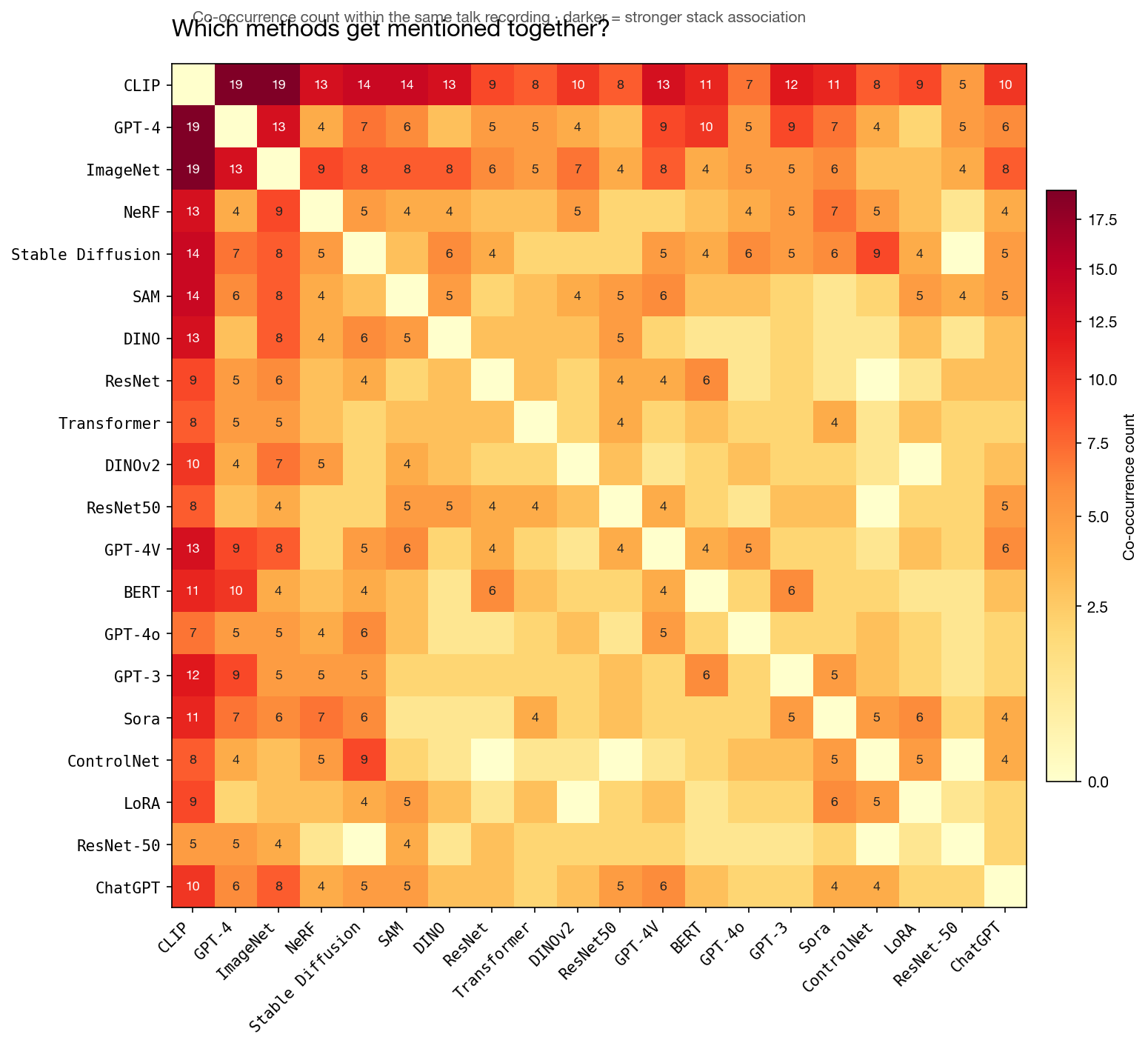
The CLIP+GPT-4+ImageNet triangle is the strongest stack association (each pair co-occurs in 13-19 videos). ControlNet and Stable Diffusion co-occur 9 times — the dominant text-to-image controllability story. NeRF and ImageNet appear together more than NeRF and Gaussian Splatting — the older guard still co-cites the canonical benchmark.
Theme coverage
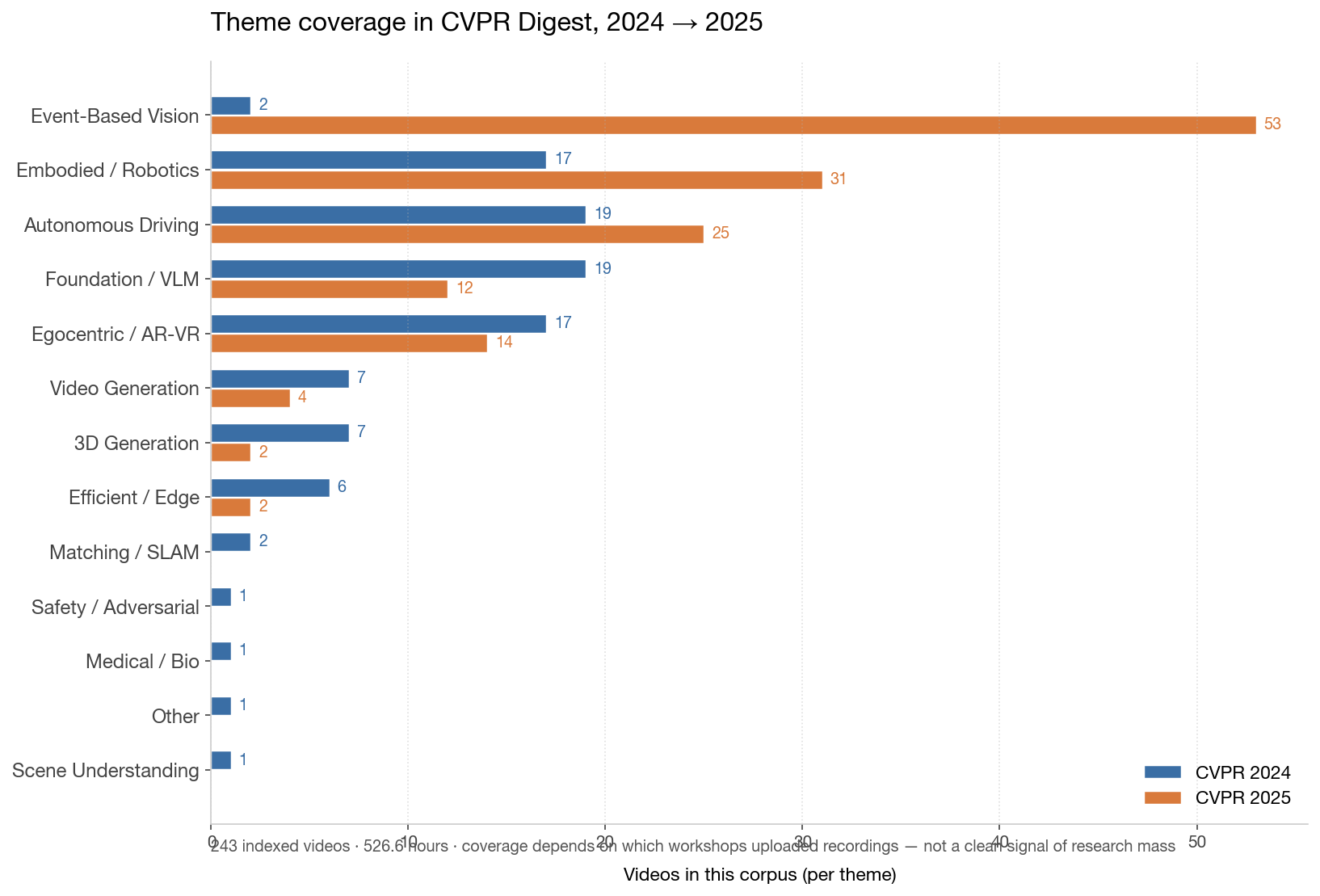
A note on this chart: the apparent Event-Based Vision explosion in 2025 reflects the corpus, not the field. The CVPR 2025 Event-Based Vision workshop uploaded four dedicated YouTube playlists (~99 videos); most other 2025 workshops uploaded zero or one. Theme breakdown here is honest about what got indexed, not what got published.
Numbers
| Videos indexed | 235 |
| Total source content | 526.6 hours |
| Individual talks identified | 1,687 |
| Unique speakers | 1,433 |
| Unique named methods / models / datasets | 7,041 |
| CVPR 2024 (workshop & tutorial recordings) | ~100 |
| CVPR 2025 (paper teasers + workshop sessions) | ~135 |
How to navigate
- By year: 2024 · 2025
- By theme (within each year): autonomous driving, embodied robotics, 3D generation, event-based vision, foundation models, efficient vision, medical imaging, remote sensing, AR/VR, …
- By method: methods/ — find every video where
CLIP,Stable Diffusion,Gaussian Splatting,GAIA-1, etc. appear - By speaker: speakers/ — who’s been talking about what
Caveats
- Structured extractions are heuristic, not citations. Speaker names, affiliations, timestamps are usually right but not guaranteed — verify before quoting.
- Some CVPR 2025 workshop pages embed older paper teasers (CVPR 2019/2020/2021) as recommended reading; the
eventfield in each page identifies the original year. - A handful of multi-hour workshop pages are marked
partial: truein frontmatter — they have most but not all segments extracted.
License
- Notes content (
2024/,2025/,methods/,speakers/): CC BY 4.0 - Underlying VIDEO content remains the property of its original creators (presenters, workshop organizers, the Computer Vision Foundation). This project does not redistribute video — only structured summaries derived from public YouTube recordings, with links back to the originals.
Contributing
PRs welcome:
- Personal “Notes” sections on individual video pages (every video has a placeholder)
- Flagging errors via issues (wrong speaker names, mistimed jump links, mis-classified themes)
- Extending to other conferences — ICCV, ECCV, NeurIPS, ICML
A project by @QihongRuan · 2026